The practical takeaway for live video teams
- TCP gives you ordered, reliable delivery, which is useful when playback quality matters more than absolute immediacy.
- It fits best at two points in the pipeline: encoder ingest and HTTP-based viewer delivery.
- Its main trade-off is latency creep under packet loss, because retransmission can delay later data.
- For sub-second interaction, I would usually look beyond TCP to a real-time transport such as WebRTC or SRT.
- The best setup depends on whether you are optimising for scale, reliability, or audience response speed.
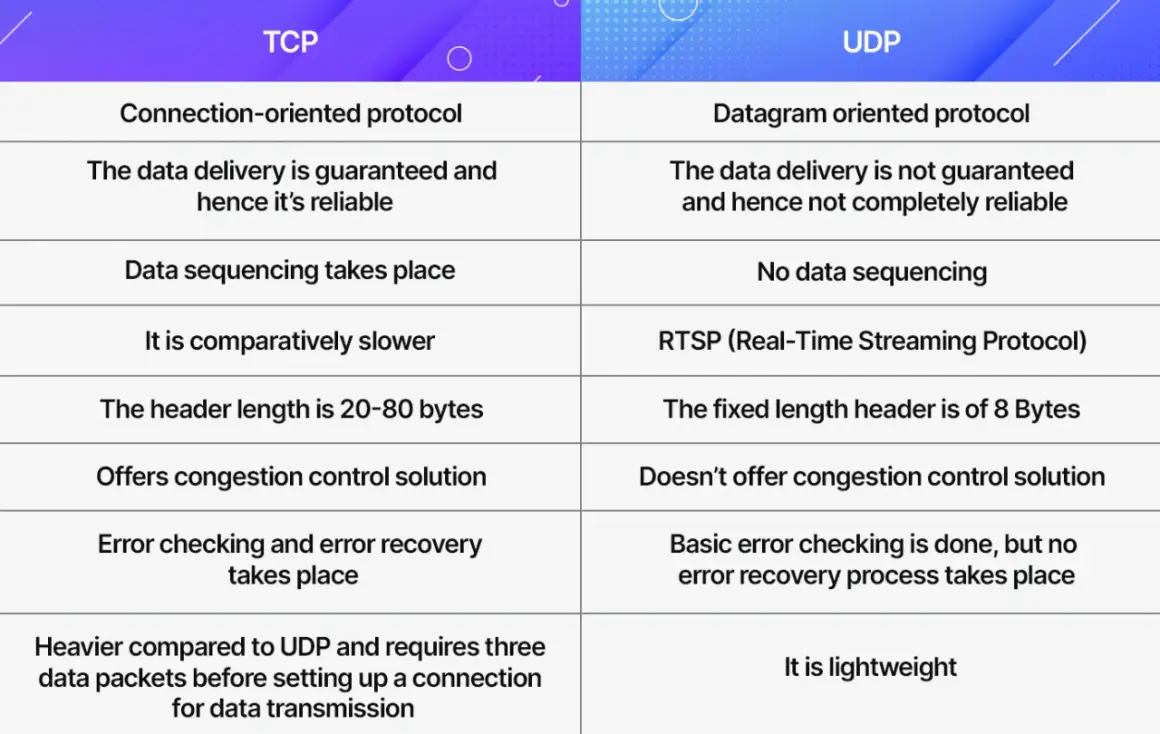
What TCP really does in a live video path
TCP, the Transmission Control Protocol, is the reliability layer most people forget about until a stream starts glitching. It moves data as a reliable, in-order byte stream, which means the application gets the same sequence of bytes that were sent, even if packets arrive late or out of order. TCP does not know anything about frames, keyframes, audio samples, or codecs; it just makes sure the transport is clean enough for the streaming protocol on top of it to assemble the media correctly.| Pipeline stage | What TCP is doing | Why it matters |
|---|---|---|
| Encoder to origin | Moves compressed media through one ordered connection | Keeps the contribution feed intact, which reduces failed publishes and corrupted segments |
| Origin to viewer | Delivers HTTP chunks or segments through the same reliable transport | Helps CDNs and players recover cleanly from loss, but buffering can grow |
That distinction matters because live video usually has two very different jobs. On the ingest side, the encoder needs to hand compressed media to a server without random corruption. On the delivery side, the viewer needs a smooth playhead and enough buffering to survive network noise. I treat those as separate decisions, even when they sit in the same broadcast pipeline, and that is what leads to the next question: why does TCP keep showing up at all?
Why it keeps showing up in live streaming workflows
TCP stays popular because it solves the boring problems that break production: packet loss, out-of-order delivery, and compatibility across networks that do not love exotic ports. It also pairs naturally with HTTP and TLS, which is why so much live delivery now rides over standard web infrastructure instead of custom transport code. In practice, that means easier firewall traversal, fewer support headaches, and a smoother path through CDNs and corporate networks.
- Encoder ingest: RTMP and RTMPS still fit well when the goal is stable contribution from OBS or hardware encoders.
- Mass playback: HLS remains the safest default when you need reach, caching, and broad device compatibility.
- Lower-latency playback: Low-Latency HLS trims delay without abandoning the HTTP model.
Apple notes that Low-Latency HLS can reach two seconds or less, and Amazon IVS documents RTMPS delivery with latency under five seconds. Those are not universal promises, but they show what is possible when the packaging, origin, player, and network all pull in the same direction. The catch is that reliability is not free; the moment the network degrades, TCP protects correctness before it protects immediacy.
Where TCP starts to hurt the experience
The biggest issue is head-of-line blocking. If one packet is lost, later data can sit and wait until TCP retransmits the missing piece, even if those later bytes were already available. In a file transfer, that is fine. In a live stream, it can turn a brief network wobble into a noticeable latency jump.
- the video still plays, but chat or reactions feel late
- latency grows during Wi-Fi interference or mobile handovers
- buffering increases while bitrate charts look deceptively normal
- the stream recovers, but the delay never fully shrinks back
Each retransmission costs at least one more network round trip, so a short burst of loss can become a visible delay spike. That is why I do not treat high bitrate as the only risk. A stream can look healthy on throughput and still feel sluggish because retransmissions, congestion control, and player buffering are quietly stacking delay. The more interactive the format is, the more that delay matters, which brings us to the actual protocol choices.
The TCP-based workflows I would actually choose
I separate TCP-based live workflows into contribution and distribution, because that is where the trade-offs become obvious.
| Workflow | How it uses TCP | Best for | Main limitation |
|---|---|---|---|
| RTMP / RTMPS ingest | Persistent TCP session from encoder to origin, commonly on ports 1935 or 443 | Stable encoder-to-server contribution | Not ideal as the final viewer path |
| Standard HLS delivery | HTTP segments over TCP | Large audiences and CDN-backed playback | Higher delay than real-time transport |
| Low-Latency HLS | HTTP partial segments over TCP | Lower-latency viewing at scale | Requires stricter player and packaging support |
In a new public broadcast in 2026, I would usually keep TCP on the ingest side unless there is a strong reason not to. For viewer delivery, I would start with HLS or Low-Latency HLS and only move away when the product truly needs conversational latency. RTMPS is especially useful on restrictive networks because port 443 behaves like ordinary web traffic, which keeps the path easier to traverse.
How I choose between scale, latency and reliability
For UK venue workflows, I pay close attention to the actual upload line, venue Wi-Fi congestion, and any 5G backup path, because those are the variables that decide whether TCP feels dependable or merely slow. The transport choice is never abstract in the field; it is shaped by the room, the network, and the audience expectation.
| Primary goal | My default choice | Why |
|---|---|---|
| Large audience with minimal operational risk | Standard HLS | It scales well and is easy to support across devices |
| Low-latency playback at scale | Low-Latency HLS | It keeps the HTTP model while cutting delay |
| Encoder contribution from a remote site | RTMP or RTMPS | It is mature, widely supported, and easy to integrate |
| Sub-second interaction | WebRTC or another real-time transport | TCP is usually the wrong fit for that latency target |
| Unstable remote contribution | SRT or a similar loss-tolerant transport | It handles difficult networks better than forcing TCP to do everything |
If the audience only needs to watch, TCP-based distribution is the sensible default. If the audience must respond quickly, I start moving interactivity out of the delivery path and use a transport that tolerates loss without waiting on old packets. The choice is not ideological; it is a practical trade between reach, responsiveness, and how much network risk you are willing to absorb.
The checks I run before shipping a live pipeline
The most effective changes are usually boring, which is exactly why they work. I want the pipeline to fail less often, recover faster, and avoid adding delay that nobody asked for.
- Measure real uplink, not advertised speed. Test from the venue, at the same time of day you will go live.
- Watch retransmissions and RTT. If packet loss rises, expect delay to rise with it.
- Match encoder cadence to the packaging strategy. Bad keyframe timing can make a TCP-delivered stream feel slower than it should.
- Keep buffering intentional. A tiny buffer can look impressive in tests and fail the moment the network jitters.
- Use TLS where the protocol supports it. RTMPS or HTTPS keeps the stream easier to move through modern networks.
- Plan a fallback path. If the primary route breaks, a second ingest or delivery option saves the show.
The mistake I see most often is treating latency as one knob. It is not. The transport, the protocol packaging, the encoder, the player buffer, and the network are all contributing at once, which means the fix usually comes from removing one bottleneck rather than rewriting the whole stack. That is the last point I want to leave you with before we close this out.
The rule I use when the stream must feel live
When the goal is wide reach and stable playback, I keep TCP in the chain and tune the video workflow around it. When the goal is immediate conversation, live bidding, or rapid audience reaction, I stop asking TCP to behave like a real-time transport and move that part of the experience to a lower-latency option. In other words, I use TCP where reliability matters most, and I avoid forcing it to solve problems it was never designed to solve.That split is usually the difference between a stream that merely works and one that actually feels live to the viewer.