A relay layer becomes important the moment a live video session has to survive hotel Wi-Fi, corporate firewalls, mobile carrier NAT, or a viewer behind a strict router. A coturn server gives you TURN, STUN, and relay handling so WebRTC media can connect when a direct path fails. In this article I break down what it does, when it actually helps streaming and live video, and how I would configure it without adding avoidable latency or risk.
Key points to keep in mind before you deploy a relay
- STUN helps a client discover its public address; TURN carries the media when direct connectivity fails.
- It matters most for interactive WebRTC live video, guest callers, and locked-down networks.
- It is not a replacement for CDN-based HLS or DASH delivery.
- In production, choose one authentication model, open only the ports you need, and keep the relay close to your users.
- Bandwidth is usually the first real limit, not CPU.
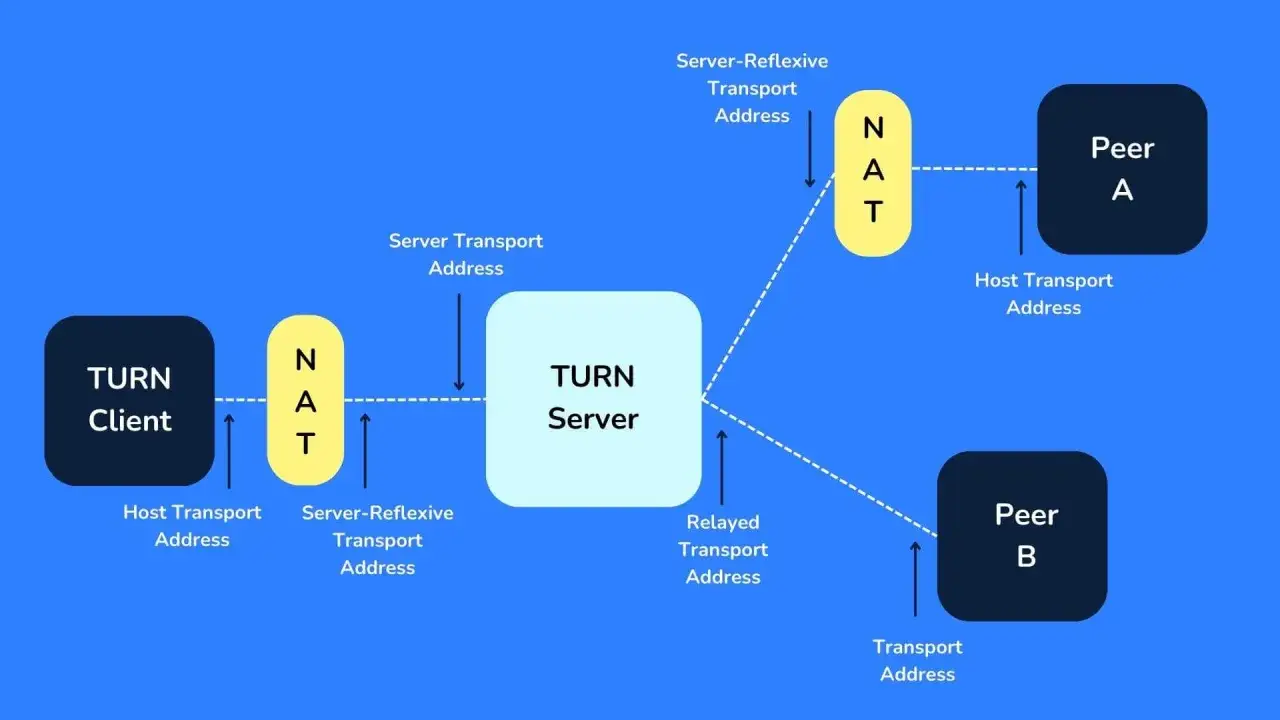
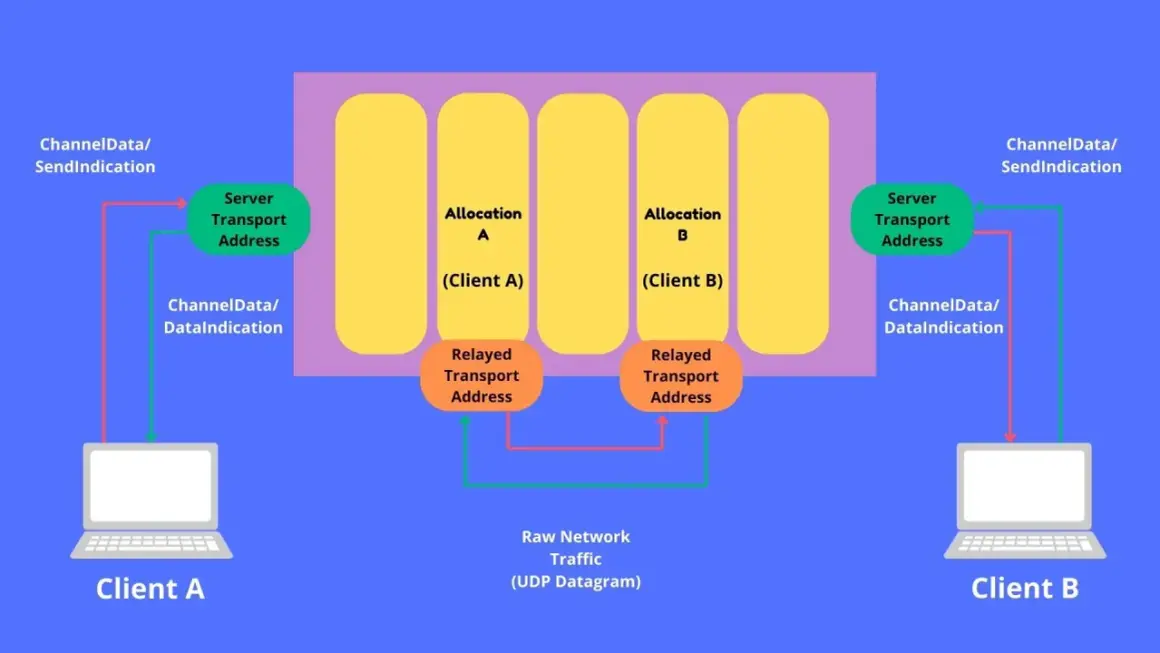
How the relay fits into a live video path
When I look at live video infrastructure, I separate signalling from media transport. Signalling sets up the session; the media path is what actually carries audio and video. ICE (Interactive Connectivity Establishment) is the decision layer that tests candidate routes and keeps the best one. STUN tells the client what public address it appears to have, while TURN takes over when direct routing is blocked or too unreliable.
| Path | What happens | Strengths | Weaknesses | Best fit |
|---|---|---|---|---|
| Direct peer connection | Media flows without a relay | Lowest latency, lowest cost | Fails behind strict NATs and firewalls | Same LAN or friendly networks |
| STUN-assisted direct path | The client learns its public-facing address and tries direct ICE candidates | Still low latency, no media relay | Not enough for symmetric NAT or restrictive networks | Many consumer connections |
| TURN relay | Media goes through the relay server | Highest reachability, predictable fallback | Extra bandwidth, extra ops and security work | Corporate Wi-Fi, mobile networks, guest calls |
For most live-video stacks, the relay is not the first choice. It is the safety net that keeps the session alive when the network gets in the way. That distinction matters, because it changes what you should build next.
When you actually need it and when you do not
If your stream is interactive and browser-based, I would expect relaying to be part of the design. Remote interviews, live shopping, virtual events, telehealth, classroom sessions, and backstage production feeds all run into real-world NAT issues. The relay becomes the difference between a session that works on the office LAN and one that survives the open internet.
Good fits
- Two-way live interviews where guest callers join from unpredictable networks.
- Interactive webinars where presenters and moderators are both in the browser.
- Remote production tools that need a reliable fallback path for video and audio.
- Private live rooms for internal meetings, training, or support sessions.
- Mobile-first live experiences where users may move between networks mid-session.
Poor fits
- One-way broadcast streaming that already uses HLS or DASH through a CDN.
- Archived or delayed video where latency is not the main problem.
- Simple file delivery or download workflows.
- Workloads that never rely on browser-to-browser connectivity.
If your pipeline is more like camera to encoder to CDN to player, TURN is usually the wrong tool. If your pipeline depends on WebRTC, guest participation, or live interaction, it is often the fallback that makes the product feel dependable. That is the point where deployment details start to matter.
A practical deployment pattern that keeps the service simple
I prefer to treat relaying as an edge service: public, tightly scoped, and close to the media server or audience it serves. For a UK-facing platform, I would usually start with a London region or the nearest stable UK edge rather than placing the relay far away and hoping the extra hop does not show up in user perception.
| Setting | Why it matters | What I would do |
|---|---|---|
listening-port=3478 |
Plain TURN/STUN traffic usually starts here | Expose it only if your clients need non-TLS access |
tls-listening-port=5349 |
Secure TURN over TLS/DTLS | Enable it when policy, browsers, or enterprise networks expect encrypted transport |
fingerprint |
Adds message fingerprints for integrity checks | Turn it on in production |
realm |
Used by long-term credentials and TURN REST setups | Keep it stable and tied to your service identity |
use-auth-secret |
Supports time-limited credentials for web apps | Use it when your application mints temporary access for users |
lt-cred-mech |
Classic long-term authentication model | Use it if you manage persistent user accounts on the relay side |
external-ip |
Fixes public/private address mapping behind NAT or in containerised setups | Set it explicitly if the server is not directly on a public IP |
denied-peer-ip |
Blocks relay traffic to private or internal addresses | Use it as a safety barrier against unintended internal access |
The upstream container example exposes 3478, 5349, and a wide UDP relay range, but I would not copy that pattern blindly. Start with the narrowest relay range that fits your concurrency, then widen it only if monitoring shows that you actually need the headroom. If the server sits behind NAT, make sure the public address mapping is correct before you test from outside the cloud network. That avoids a lot of false debugging later.
The one deployment mistake I see repeatedly is people assuming that the relay is just another app server. It is not. It is a public transport service for media, and it behaves more like a network appliance than a normal web backend. That is why security needs its own section.
Security and abuse control matter more than most teams expect
I treat relaying as a public edge workload. It needs authentication, it needs destination restrictions, and it needs to fail safely. A TURN relay that can reach private subnets or metadata endpoints is not just a video component anymore; it becomes a potential pivot point.
Authentication first
- Use one authentication model, not both. In coturn,
use-auth-secretandlt-cred-mechare not something I would mix casually. - Prefer time-limited credentials for web apps, because they fit browser-based live video better than static passwords.
- Avoid anonymous access outside of lab tests.
- Keep your realm and secrets stable, and rotate them with a real process instead of ad hoc changes.
Read Also: Live Streaming Platforms - Which Is Best For You?
Guardrails that save you later
- Block loopback, RFC1918, and other internal ranges so the relay cannot be used to reach infrastructure it should never touch.
- Separate the relay from internal application servers, databases, and management networks.
- Apply user quotas, total quotas, and bandwidth caps where the implementation supports them.
- Watch auth failures, allocation spikes, and relay destination patterns for signs of abuse or misconfiguration.
- Patch quickly. A public relay does not deserve a slow update cycle.
That security posture sounds strict, but in practice it is what keeps the relay boring. Boring is good here. Once the access model is safe, the next question is how much traffic the box can realistically carry.
How to size bandwidth and latency for live traffic
Capacity planning for a relay is mostly a bandwidth exercise. CPU matters, but network throughput tends to be the first ceiling you hit. I size from the relayed media, not from the number of usernames in a database. A single relayed stream is already traffic in both directions, and one stream fanning out to many viewers grows fast on the server side.
A useful rule of thumb is to budget for the media bitrate plus headroom, then check whether your relay traffic is mostly interactive or fan-out. Interactive calls usually stress both directions. Fan-out live sessions are trickier, because each relayed viewer adds its own forwarding load. I usually add 10 to 20 percent overhead for packet overhead, bursts, and the fact that real traffic is never as neat as the diagram.
The project itself describes TURN mode as capable of handling thousands of simultaneous calls per CPU under the right conditions, and tens of thousands when only STUN is involved. I would treat that as a rough capacity signal, not a guarantee. In production, the real limiter is often the network card, the cloud egress bill, or a sudden rise in fallback traffic.
| Signal | What it tells you | Why I watch it |
|---|---|---|
| Fallback-to-relay rate | How often direct ICE fails | High values usually mean a network or firewall problem, not just scale |
| Egress Mbps | How hard the relay is pushing bytes out | Usually the fastest way to find the real ceiling |
| Allocation count | How many relay sessions are active | Useful for understanding concurrency and growth |
| Auth failures | Bad credentials or abuse attempts | Separates normal traffic from operational trouble |
| RTT and packet loss | User experience under relay | Helps you tell the difference between reachability and quality problems |
If your fallback rate jumps after a release, I would look for a network change before I blame server capacity. A broken port rule, a wrong certificate, or a mis-set public address can look like overload from the outside. That is why the rollout itself deserves a clear checklist.
The rollout choices that save the most pain later
For a UK live-video launch, I would keep the first version conservative and close to the user base. The goal is not to build the biggest relay platform possible. The goal is to make the network layer disappear so the stream feels stable.
- Place the relay in the same region as the media server or audience when you can, and start with a UK region for UK-first traffic.
- Test from home broadband, 5G, corporate Wi-Fi, and guest Wi-Fi before you call the setup production-ready.
- Open
3478and5349only if your client mix really needs them, then keep the relay port range as narrow as possible. - Choose your authentication model up front, because changing it later means retesting every client path and credential flow.
- Track the ratio of successful direct ICE connections to relay fallbacks, because that ratio tells you whether the relay is a safety net or a crutch.