
The stack only works when transport, delivery, and monitoring are designed together
- Ingest is where many failures start: weak uplinks, unstable encoders, or no backup path.
- HLS + CDN is still the safest default for large audiences; LL-HLS narrows delay without giving up scale.
- SRT is a stronger choice for contribution over the public internet when resilience matters.
- WebRTC fits interactive sessions where speed matters more than sheer audience size.
- 1- to 2-second keyframes and short, well-tested segments are the practical baseline for lower latency.
- Monitoring should cover the encoder, network, origin, CDN, and player, not just the video server.
What the stream has to do before anyone sees a frame
I usually think about a live workflow as five jobs, not one. First, the camera or production switcher captures the signal. Then the encoder compresses it into a transport-friendly format. After that, the feed crosses a network, gets packaged for playback, and finally reaches viewers through a delivery layer that can handle real-world scale.
The important part is that each job changes the risk profile. Capture and encoding are mostly about quality and stability at the source. Transport is about surviving packet loss, jitter, and upload problems. Delivery is about how many people can watch at once and how quickly playback starts. If you blur those layers together, you end up buying the wrong fix for the wrong problem.
I also separate latency from scale. A fast interactive stream is not the same thing as a stream that can handle tens of thousands of viewers. Once that is clear, the next step is to choose the components that belong in each layer and avoid overengineering the parts that are already strong.
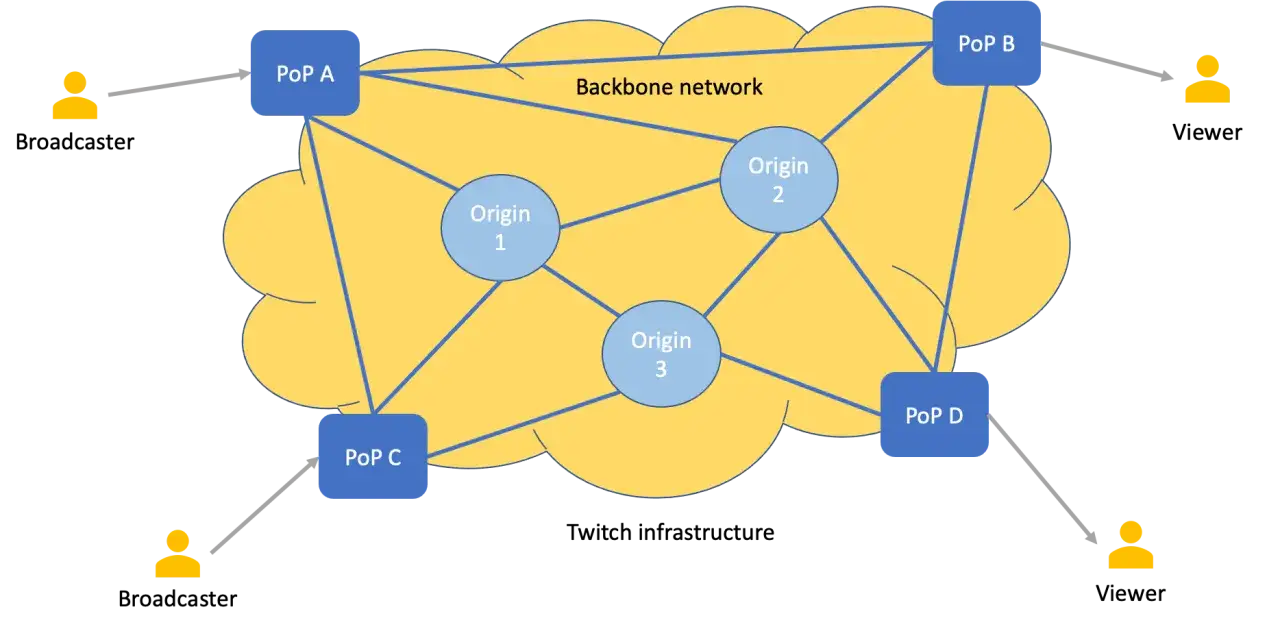
The components I would not leave out
When I map a production stack, I start with the same core layers AWS uses in its live streaming reference architecture: ingest, processing, origin, delivery, client, and monitoring. That breakdown is useful because it mirrors the places where live streams actually fail in production. If one layer is weak, the rest of the system has to absorb the damage.
| Layer | What it does | What breaks when it is weak | What I usually aim for |
|---|---|---|---|
| Capture and production | Collects camera, audio, graphics, and switching | Poor framing, bad audio, sync drift, unstable source feeds | Dedicated hardware, clean audio, and a tested production chain |
| Encoding | Compresses video and audio into a streamable format | Dropped frames, overshooting bitrate, CPU overload | One well-tested profile, with headroom and conservative settings |
| Ingest | Receives the live feed from the encoder | Disconnects, packet loss, failed handoffs | A secure primary path plus a backup path |
| Processing and packaging | Creates adaptive renditions and playback manifests | Mismatch between segments, poor device compatibility, longer startup time | ABR renditions that match the audience mix |
| Origin and CDN | Stores and distributes the stream to viewers | Cache misses, slow startup, regional bottlenecks | HTTP-based delivery with an edge network close to the audience |
| Player and client | Decodes and displays the stream | Buffering, failed playback, device-specific quirks | Test across browsers, mobile, and smart TV devices |
| Monitoring | Tracks stream health, errors, and performance | Slow detection of failures and no clear root cause | Alerts for bitrate, packet loss, startup time, and playback errors |
The practical lesson is simple: invest first in the layers that can fail silently. A fancy player or an expensive transcoder will not save you if the ingest path is unstable. Once those layers are clear, the transport choice becomes much easier to evaluate.
How to choose between RTMP, SRT, HLS, LL-HLS, and WebRTC
Protocol choice is where a lot of teams lose time. They start by asking which one is “best,” but the real question is what the stream needs to do. Is this a contribution feed from a venue to the cloud, a one-to-many broadcast, or an interactive session where the audience must react almost instantly?
For broad delivery, HTTP-based playback is still the safest default. For contribution over unreliable internet, low-latency transport matters more. For conversational or interactive use cases, you need a protocol built for very short round-trip times. In 2026, the practical split is still clear: HTTP/CDN for reach, SRT or RTMP for contribution, and WebRTC for interaction.
| Protocol | Best for | Strengths | Trade-offs |
|---|---|---|---|
| RTMP / RTMPS | Encoder to platform or cloud ingest | Widely supported, simple to configure, still common in tools | Not ideal as the final delivery format, and latency is not its strength |
| SRT | Contribution over the public internet | Designed for secure, low-latency transport and better handling of loss and jitter | Requires compatible endpoints and a little more workflow planning |
| HLS | Mass-audience delivery | Scales well through ordinary web infrastructure and CDNs | Traditional latency is higher than real-time transport |
| LL-HLS | Low-latency delivery at scale | Brings latency down without losing the scalability of HTTP delivery | More sensitive to packaging, buffering, and cache behavior |
| WebRTC | Interactive live sessions | Very low latency, browser-friendly, good for two-way experiences | Harder to scale to very large audiences and usually more expensive to operate |
How I would tune bitrate, latency, and redundancy
This is the part where teams often overcomplicate things. I would rather see one stable encoding profile and a clean failover plan than three half-tested “optimizations.” The goal is not to squeeze every last millisecond out of the system; it is to keep the stream watchable when the network is not cooperating.
As a starting point, I keep video settings conservative enough to survive ordinary uplink fluctuations. For most workflows, that means keeping keyframes every 1 to 2 seconds, because that gives packaging and recovery a sensible rhythm. Apple’s HLS authoring guidance still points to nominal 6-second segments, which is a good reminder that latency and stability always trade off against one another.
| Setting | Practical starting point | Why it matters |
|---|---|---|
| 720p30 bitrate | 2.5 to 4.5 Mbps | Good starting range for smaller events and easier uplinks |
| 1080p30 bitrate | 4.5 to 6 Mbps | Balanced quality for most corporate, educational, and creator workflows |
| 1080p60 bitrate | 6 to 9 Mbps | Useful for sports, motion-heavy scenes, and cleaner UI capture |
| Keyframe interval | 1 to 2 seconds | Helps segmenting, recovery, and predictable playback behavior |
| Audio codec | AAC-LC at 128 to 192 kbps | Reliable, widely supported, and usually enough for spoken word plus music |
| Redundancy | Dual encoders or at least a backup ingest path | Keeps one failure from killing the entire event |
Latency needs to be defined before you start tuning. If the stream is meant for chat-driven interaction, you need a much tighter budget than if you are broadcasting a keynote or a club event. Once you shorten segments or player buffers, you also increase request volume and sensitivity to CDN or origin problems. That is not a reason to avoid low latency; it is a reason to test it properly.
For resilience, I like to think in layers again: a second encoder, a second uplink, and a second route into the platform are more valuable than another small quality tweak. If you cannot afford all three, I would start with the uplink and ingest path, because those are the failures most likely to cancel the stream outright. With the technical knobs set, the next question is what a realistic deployment looks like for teams in the UK.
What a practical UK deployment looks like
For UK teams, the biggest mistake is assuming that a strong office connection automatically means a strong live event. It does not. Venue Wi-Fi can be unpredictable, mobile coverage varies by building, and audience playback often depends more on edge delivery than on your studio’s headline bandwidth. I care far more about upload stability, peering quality, and backup connectivity than about theoretical peak speeds.
A sensible setup in the UK usually starts with a clear audience model. For a webinar or product demo, I would use a dedicated laptop or hardware encoder, a wired microphone, a clean camera feed, and a delivery path that ends in HLS or LL-HLS through a CDN. For a regional event or a venue with a history of flaky internet, I would add a separate network path, ideally a mobile backup on another provider or a dedicated line.
If the audience is mostly domestic, I would prefer a CDN with strong UK edge coverage and test from more than one city. London is not enough. I would at least spot-check from Manchester, Glasgow, and Cardiff-style usage patterns, because latency and startup time can vary enough to change the viewer experience. If the stream includes chat, registration, or recording, I would also keep an eye on data handling and retention so the production workflow does not become a compliance headache later.
That is especially important for public-facing organisations, schools, clubs, and agencies, where the operational detail matters as much as the video quality. The next section is where most teams save the most time: avoiding the repeatable mistakes that cause stutter, delay, and downtime.
The mistakes that usually cause dropped frames and long delays
Most live failures are boring in hindsight. They come from a small set of avoidable mistakes rather than from one dramatic technical flaw. The good news is that these errors are predictable, which means they are fixable before the next event.
| Symptom | Likely cause | What to change |
|---|---|---|
| Buffering after a few minutes | Bitrate is too aggressive for the real uplink | Lower the bitrate, reduce resolution, or use a more stable contribution path |
| Good studio quality but poor viewer playback | Packaging, CDN caching, or player buffering is off | Check manifest freshness, cache rules, and player startup settings |
| Delay keeps growing during the event | Segments are too long or the player buffer is too conservative | Shorten the live window and test LL-HLS or WebRTC if interaction matters |
| Stream dies when the venue network blips | No backup ingest or backup network | Add redundancy at the network and encoder layer, not just in software |
| Audio and video drift apart | Timestamp problems, mismatched frame rates, or poor transcode settings | Lock frame rate, verify sync early, and avoid unnecessary format changes |
| Hard to diagnose failures | No metrics from encoder, origin, CDN, or player | Log bitrate, packet loss, startup time, and playback errors in one place |
The pattern I see most often is this: teams blame the platform when the real issue is a bad assumption earlier in the chain. If the encoder is unstable, no player tweak will rescue the experience. If the player is overloaded, no amount of upstream bitrate tuning will matter. That is why I prefer to isolate the failure domain before changing anything.
Once you know where the stream is actually breaking, the fixes get smaller and cheaper. That is the point where a lean, well-tested workflow beats a complicated one every time. From there, the last decision is not technical glamour; it is prioritisation.
What I would build first if I had to start from zero
If I were starting from scratch, I would build in this order: source quality, encoding stability, ingest resilience, delivery scale, and then latency tuning. That sequence keeps the expensive mistakes small. It also stops teams from spending money on features they cannot yet support operationally.
My minimum viable setup would include a reliable camera and microphone, a dedicated encoder or streaming machine, a stable wired connection, a backup path, and a delivery layer built around HTTP-based playback. If the use case needs interaction, I would move the audience side toward WebRTC or narrow the HLS delay with a low-latency configuration. If the use case is mostly one-to-many, I would keep the architecture simpler and spend more effort on monitoring and failover.
The most useful habit is to define what failure you can least afford. If it is lost reach, prioritize delivery resilience. If it is lag, prioritize protocol choice and buffering. If it is an outright outage, prioritize ingest redundancy and network failover first. In practice, I would rather have one well-tested path from camera to viewer than a stack full of half-used options, because that is what keeps live video dependable when the real event starts.