
The practical version at a glance
- HLS and MPEG-DASH are the safest defaults when you need scale, adaptive bitrate delivery, and broad device support.
- WebRTC is the better fit when people need to talk back, react quickly, or collaborate in real time.
- SRT and RIST are contribution tools first, not viewer playback formats.
- RTSP/RTP still matter in camera and legacy IP-video environments, but they are not the first choice for modern public delivery.
- Latency is a workflow decision, not a single toggle. Encoder settings, segment size, buffering, and network quality all shape the result.
What the transport layer actually decides
I start by separating the job into four questions: how media is packetised, how it survives loss, how much delay the system tolerates, and whether the viewer can adapt to changing bandwidth. That is why protocol choice matters more than most codec debates. A codec changes compression efficiency; the transport layer changes how the stream behaves on the wire.
In live video, I usually think in four roles:
- Adaptive HTTP delivery for broad distribution, where segments and manifests make playback resilient and scalable.
- Interactive delivery for situations where response time matters more than mass reach.
- Contribution transport for getting clean video from a venue, remote studio, or field location into production.
- Session control for systems that separate control messages from the actual media carriage.
Once you separate those roles, it becomes obvious why no single protocol is ideal for every use case, and that is what the next section makes clear.
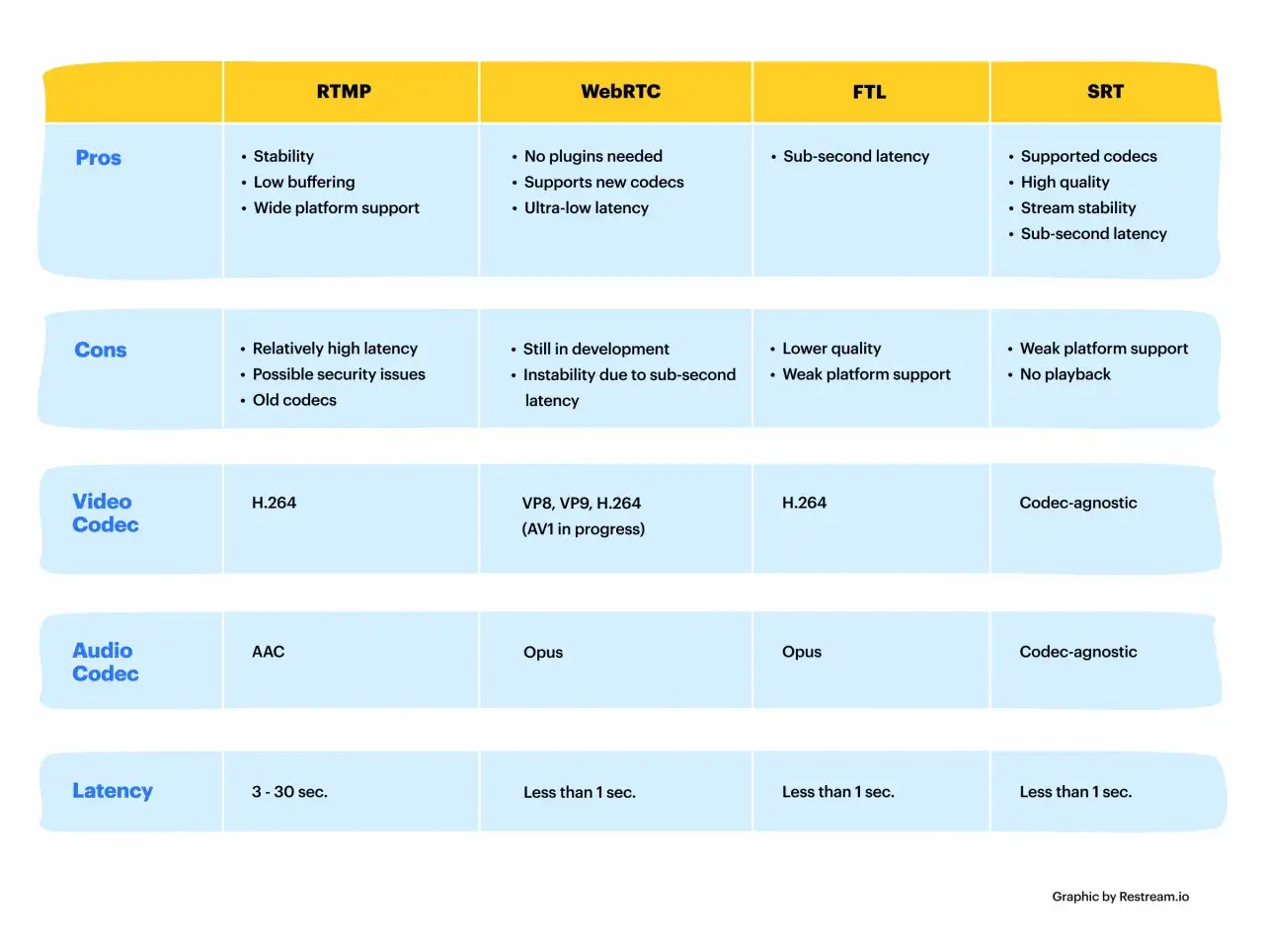
How the main live video protocols differ
In 2026, the cleanest way to compare these tools is by the job they do, not by the label on the spec sheet. Some are built for huge audiences, some are built for interactivity, and some are built to survive ugly networks on the way into a production chain.
| Protocol family | Best use | Why it fits | Main trade-off |
|---|---|---|---|
| HLS | Large audience streaming | Runs over ordinary web servers and CDNs, which makes it easy to scale and cache. | Latency is usually higher than realtime delivery. |
| Low-Latency HLS | Audience streams that need less delay | Keeps HLS’s CDN-friendly model while reducing delay. Apple’s Low-Latency HLS extension is designed for a stream delay of two seconds or less. | Less forgiving than traditional HLS if packaging, buffering, or playlist timing is sloppy. |
| MPEG-DASH | Standards-based adaptive streaming | Uses existing HTTP infrastructure and works well when you want an open, device-agnostic delivery model. | Implementation details vary more by platform than people expect. |
| WebRTC | Interactive live video | Built for real-time communication between peers, with very low delay and browser-native support. | Not the simplest way to serve a massive passive audience. |
| SRT | Contribution over imperfect networks | Designed for secure, low-latency video across unpredictable links, with strong packet-loss recovery and jitter handling. | It is a transport layer, not a finished viewer experience by itself. |
| RIST | Reliable contribution links | Focuses on low-latency, resilient delivery over lossy networks and is attractive when interoperability matters. | Its ecosystem is smaller on the playback side. |
| RTSP/RTP | Camera control and legacy IP video | RTSP controls media sessions; RTP carries the real-time media. That split is useful in older or specialised systems. | Usually not the cleanest path for modern public streaming. |
My rule of thumb is simple: use HTTP-based adaptive delivery when you need scale, use WebRTC when the interaction has to feel immediate, and use SRT or RIST when the network between endpoints is the weak link. Once you see those trade-offs, the next step is choosing the right option for the actual workflow instead of the abstract technology.
How I choose one for a real workflow
I choose by latency target first, then audience size, then network quality. That order matters because teams often start with the platform they like and only later discover that the real constraint was the delivery model all along.
When delay must stay extremely low
If the event depends on turn-taking - auctions, live shopping, remote direction, live classrooms, or audience Q&A - I reach for WebRTC at the front end. It is built for real-time communication, which makes it the right answer when response time matters more than endless scale. The catch is that WebRTC is not the easiest way to push one feed to hundreds of thousands of passive viewers.
When scale matters more than instant interaction
For a public broadcast, I prefer HLS or DASH because they sit comfortably on HTTP infrastructure and CDNs. That makes them easier to cache, easier to monitor, and easier to recover when the network is uneven. Apple’s Low-Latency HLS extension narrows the gap, but it still keeps the operational model of HLS intact, which is why it is so useful for large audience streams.
Read Also: Fix Live Stream Delay - Make Your Content Instant
When the network is the weakest link
For contribution from an event venue, field location, or remote production site, I favour SRT or RIST. They are designed to survive packet loss, jitter, and unstable links without asking the operator to rebuild the entire network. For a UK production team, that matters because the last mile can be excellent in one city and messy in another, especially once mobile tethering or shared Wi-Fi enters the picture.
So the real question is not which protocol is modern, but which one fits the job. That question takes you straight into the workflow itself, because the chain only works when each hop is doing the right kind of work.
The delivery chain I would use in 2026
When I build a live setup now, I split it into five steps. Each one has a different failure mode, and trying to make one component solve all five usually creates problems later.
- Encode for the delivery target. Match resolution, bitrate ladder, audio layout, and keyframe interval to the platform you actually serve. If you package in 2-second segments, keep keyframes on the same rhythm.
- Ingest on the right transport. Use SRT or RIST for remote contribution, or HTTP ingest when the packager or origin expects CMAF fragments over POST or PUT. The DASH-IF ingest model formalises that HTTP-based approach, which is useful when you want the ingest side and the distribution side to speak the same language.
- Keep the ingest path efficient. If you are using HTTP ingest, persistent connections are worth keeping. Repeated reconnects add avoidable delay and make failure handling noisier than it needs to be.
- Package for playback. Split media into aligned segments, generate manifests, and keep audio, captions, and timed metadata in step. This is where the broadcast-style discipline matters most, because a sloppy segment boundary shows up as buffering or awkward drift later.
- Distribute through the right path. Use a CDN for mass viewing; use WebRTC only where real-time interaction is part of the product. If you need viewer scale and predictable delivery, ordinary web infrastructure is still hard to beat.
The important point is that the chain is only as strong as its least disciplined step. Once the chain is built properly, the next failures usually come from avoidable configuration mistakes rather than the protocol itself.
The mistakes that cause buffering and drift
Most live-stream failures look mysterious from the outside, but the root cause is often boring. I see the same few mistakes again and again:
- Mismatched GOP and segment length. If keyframes do not land where segments begin, playback becomes less efficient and live clipping or ad insertion gets harder.
- Trying to make one transport do everything. A viewer stream, a contribution feed, and a producer intercom solve different problems. Forcing one protocol to cover all three usually creates compromise where you least want it.
- Ignoring packet loss until launch day. SRT and RIST exist because real networks are not clean lab networks. If you only test on office fibre, you miss the conditions that actually break live events.
- Confusing low latency with no buffer. A small buffer is still necessary. Remove it completely and you trade delay for instability, which is rarely a good deal for the audience.
- Overlooking firewall and NAT behaviour. WebRTC, RTP-based systems, and contribution links each have different traversal needs. If the network team is not involved early, the stream pays for it later.
- Leaving audio sync as an afterthought. Viewers forgive a little delay more easily than they forgive lip-sync drift or inconsistent dialogue levels.
The fix is usually practical rather than glamorous: align segments with keyframes, test on bad networks, and accept a little delay if the stream must remain watchable. That leads to the last thing I would lock down before going live.
What I would lock in before the first live stream
If I were building a new live stack today, I would make these decisions before the first public stream, not after the first incident report:
- Define the primary use case. Decide whether the product needs interaction, broadcast scale, or contribution resilience.
- Choose a primary and fallback path. One path for the happy route and one for failure recovery is usually enough. More than that, and the workflow starts to fight itself.
- Set latency, segment size, and keyframe cadence together. Those settings are linked, so changing one without the others creates avoidable drift.
- Test on constrained networks. Run the stream over 4G or 5G, weak Wi-Fi, and deliberately messy conditions before launch day.
- Validate captions, audio, and failover. The audience notices missing accessibility data and broken failover faster than engineering teams usually expect.
- Monitor the right metrics. Startup time, rebuffer ratio, and end-to-end delay tell you more than a clean encoder dashboard does.
If I am planning for a UK audience, I also assume mixed home broadband, mobile data, and office Wi-Fi in the same viewing session. That one assumption changes the whole design brief, because the best live stack is not the one with the lowest theoretical delay, but the one you can operate reliably when the network is imperfect. The right transport layer is the one that keeps the stream usable when reality stops looking like the test bench.