A well-built HLS stream is not just a file sent over the web; it is a playlist-driven delivery model that keeps video playable as bandwidth changes. I’m going to break down how the protocol works, why it remains the default choice for many live services, what low-latency mode really changes, and which setup decisions matter most when you care about real viewers rather than specs on paper.
What matters most when you deploy HLS
- HLS works by splitting video into short segments and pointing the player at a manifest.
- Adaptive bitrate switching is the main reason it survives weak or changing connections.
- Standard live HLS is usually easier to scale; LL-HLS is better when delay matters more.
- A 6-second target segment remains the practical baseline for many live workflows.
- Validation, aligned audio, and sensible caching prevent most avoidable playback problems.
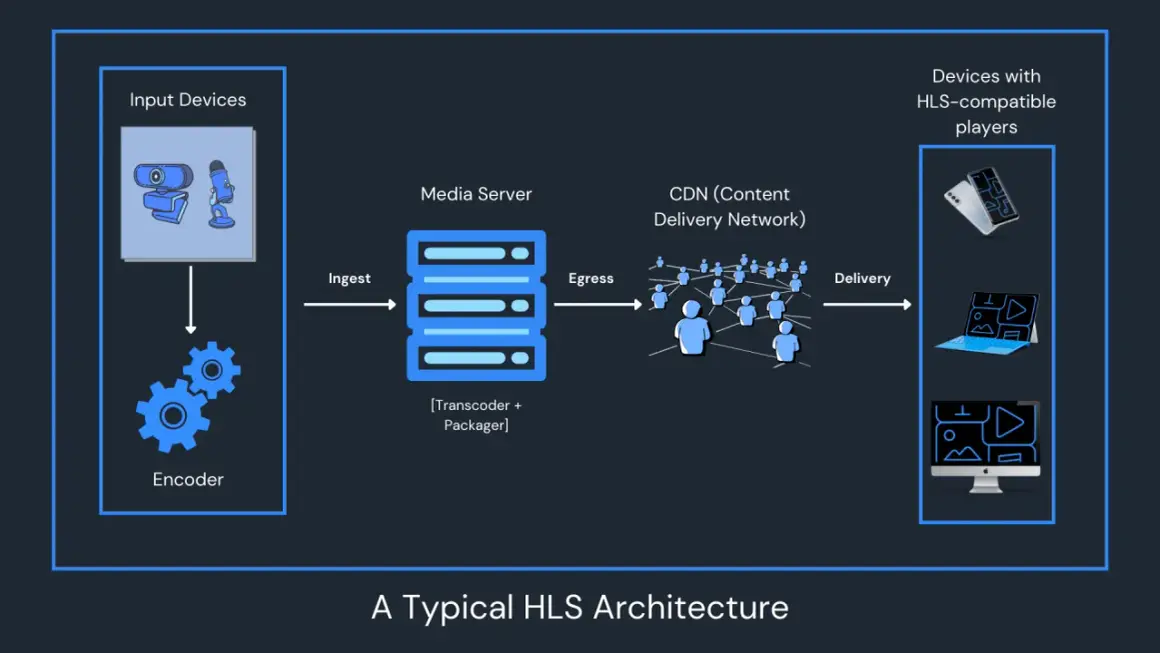
How HLS turns one live feed into something viewers can actually play
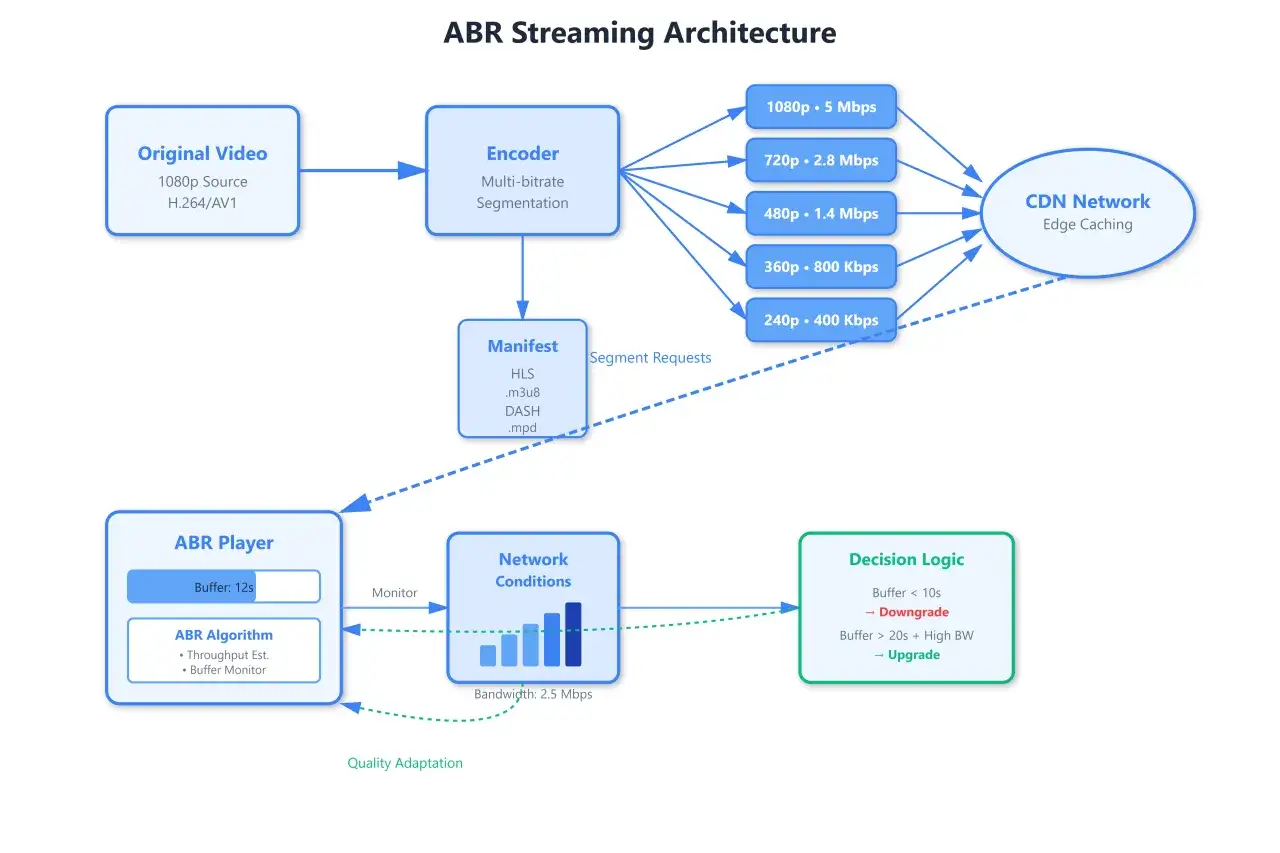
At the player level, HLS is simple to describe and surprisingly robust in practice. The device loads a.m3u8 playlist, chooses one rendition, fetches the media playlist for that rendition, then requests the short media files listed inside it. In live mode, the playlist slides forward as new segments appear and old ones fall off the list, so the viewer always follows the moving edge of the broadcast.
| Component | What it does | Why it matters |
|---|---|---|
| Master playlist | Lists the available video variants, audio groups, and subtitle options | Lets the player pick the right quality and language |
| Media playlist | Lists the current segment sequence for one rendition | Controls live playback and the moving edge of the stream |
| Media segments | Short audio and video files, often around 6 seconds in standard HLS | Make delivery cache-friendly and tolerant of network variation |
| Low-latency parts | Smaller pieces inside a segment | Reduce delay without waiting for a full segment to finish |
The key trick is adaptive bitrate switching, where the player moves between renditions as bandwidth rises or falls. A CDN, or content delivery network, is the distributed layer of edge servers that caches those segments close to viewers, and that is a big reason HLS scales so well on ordinary web infrastructure. Apple’s authoring guidance still uses a 6-second target duration as the baseline for conventional playlists, which is a useful mental anchor even if your production later shifts to shorter parts. Once you understand that flow, the next decision is whether HLS is the right transport for the experience you are trying to build.
When HLS is the right choice and when it is not
For most public live events, HLS is the pragmatic default. It scales cleanly through standard servers and CDNs, behaves well on mixed networks, and gives viewers a better chance of reaching stable playback than protocols that assume the connection will stay clean. In the UK especially, where audiences move between home broadband, office Wi-Fi, and mobile data, that adaptability matters more than many teams expect.
| Protocol | Best fit | Latency profile | Main tradeoff |
|---|---|---|---|
| HLS | Large public live events, subscription video services, and on-demand playback | Higher delay because the player buffers full segments | Very reliable, but not built for instant interaction |
| Low-Latency HLS | Sports, auctions, live commerce, and chat-heavy events | Much lower delay when the pipeline is tuned correctly | Needs tighter encoder and CDN discipline |
| WebRTC | Two-way interaction, calls, remote guests, and collaboration | Very low latency | Different scaling model from broadcast delivery |
| RTMP ingest | Contribution into an encoder or platform | Not meant for viewer playback | Useful upstream, not the final delivery layer |
If the event is a keynote, a product launch, a lecture, a church service, or a subscription channel with thousands of simultaneous viewers, I would start with HLS almost every time. If the experience depends on immediate back-and-forth, I would not force HLS to do a WebRTC job. That boundary is where a lot of streaming projects become easier to reason about, and it leads straight into the real latency question.
What low-latency HLS changes
Low-Latency HLS (LL-HLS) exists for the moments when standard buffering feels too slow. In the low-latency model, the player works closer to the live edge using smaller parts, tighter playlist reload behaviour, and less waiting for full segments to finish; the tradeoff is that you have less buffer to absorb encoder hiccups or network jitter. In plain English, you are buying speed by giving up some of the cushion that normally hides small problems.
- Use it for live sports, auctions, betting, live commerce, and social-first events where a long delay is already too much.
- Skip it when the audience mainly wants reliable viewing and the content is not time-critical.
- Expect more tuning around encoder stability, playlist updates, CDN behaviour, and player compatibility.
I tend to treat LL-HLS as a product requirement, not a default upgrade. If the business does not gain anything from shaving latency, conventional HLS is usually the calmer, safer choice. Once that choice is made, the packaging details become the real determinant of quality.
What a solid HLS setup looks like in production
A solid HLS pipeline is mostly about consistency. The best setups are not exotic; they are predictable, validated, and easy to operate when a live event starts to drift. Codec choice matters too, but I treat the codec as a compression decision, not a substitute for clean segment timing and a sensible rendition ladder.
| Setting | Good starting point | Why it matters |
|---|---|---|
| Segment duration | 6 seconds for standard live HLS | Balances compatibility, caching, and segment overhead |
| Rendition ladder | 3 to 6 video variants | Gives the player enough room to adapt without making the encoder messy |
| Audio and captions | Aligned tracks, WebVTT captions, and timed metadata such as chapter markers or ad cues | Prevents sync issues and supports accessibility |
| Playlist caching | Short cache on playlists, longer cache on segments | Keeps the live window fresh without wasting origin capacity |
| Validation | Run the stream validator before launch | Catches playlist, timing, and packaging mistakes before viewers see them |
WebVTT is the caption format I usually reach for because it keeps text tracks separate, portable, and easy to validate. Apple’s Media Streaming Validator is worth using here because it exposes problems that are easy to miss in a local test. When I build or review a stream, I care less about a fancy codec label than about whether the variants line up cleanly, the audio stays in sync, and the manifest stays readable under load. Once those basics are in place, the remaining problems are usually self-inflicted.
Common mistakes that hurt playback quality
The failures I see most often are not dramatic outages. They are small mismatches that make playback look unstable even when the stream never fully breaks.
- Changing segment length or the frame boundaries your encoder uses to cut those segments midstream.
- Building bitrate steps that are too close together, so the player keeps bouncing between them.
- Letting playlists cache for too long, which makes the live edge stale.
- Misaligning audio, video, captions, or alternate languages.
- Launching without device testing on both strong and weak networks.
- Running a single CDN path with no practical fallback.
The pattern here is simple: the player only behaves as well as the manifest and delivery chain allow it to behave. If you fix one or two of these issues, playback usually feels better immediately, which is why the final pre-launch checks are so useful.
The launch checks I would run before going live
Before I trust a live event, I try to watch it the way a normal viewer would. That means testing the stream on different devices, on different networks, and with the same impatience your audience will bring.
- Open the stream on at least one iOS player and one non-native player.
- Test the same feed on fast Wi-Fi and on a throttled mobile connection.
- Watch the first minute closely for startup delay, rebuffering, and awkward rendition switches.
- Confirm captions, alternate audio, and timed metadata appear where they should.
- Check that the live edge advances smoothly and recovery works after a brief network drop.
If I had to leave you with one practical rule, it would be this: optimise for predictable playback first, then lower latency only when the event really benefits from it. That is the difference between an HLS deployment that feels dependable under pressure and one that only works in the demo room.