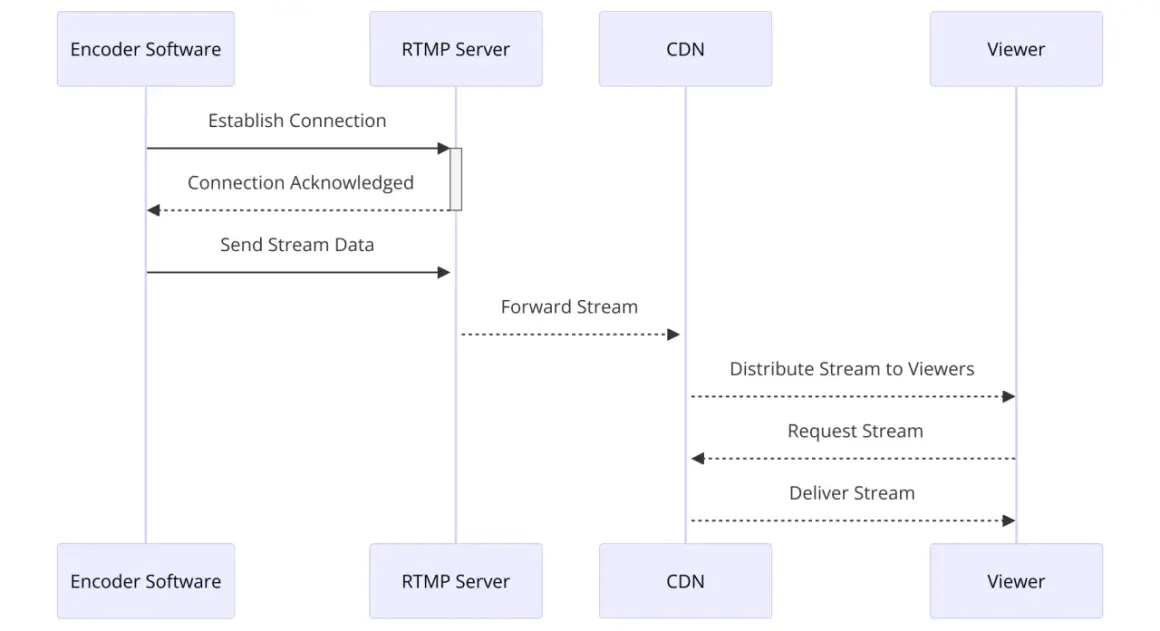
An RTMP server on Linux is still a practical choice when you need a stable ingest point, a private relay, or a simple bridge from an encoder to HLS or DASH delivery. I’m focusing on the setup choices that actually matter in production: which package path is easiest to maintain, how to write a clean NGINX configuration, how to test with OBS or FFmpeg, and how to avoid the common failures that turn live video into a support ticket. The goal is not to romanticise the protocol; it is to get a stream from camera to server without wasting bitrate, time, or patience.
What matters most is the ingest path, the playback path, and the firewall between them
- RTMP works best as ingest. I would not build a viewer-facing workflow around it in 2026.
- On Debian and Ubuntu, the packaged NGINX module is usually the fastest route. It keeps maintenance simple.
- Use TCP port 1935 for publishers and serve viewers over HTTP or HTTPS when browser playback is required.
- H.264 video and AAC audio remain the safest default. They reduce compatibility problems fast.
- Plan bandwidth with margin. A 1080p stream at 6 to 8 Mbps is often enough to start, but recording raises storage use quickly.
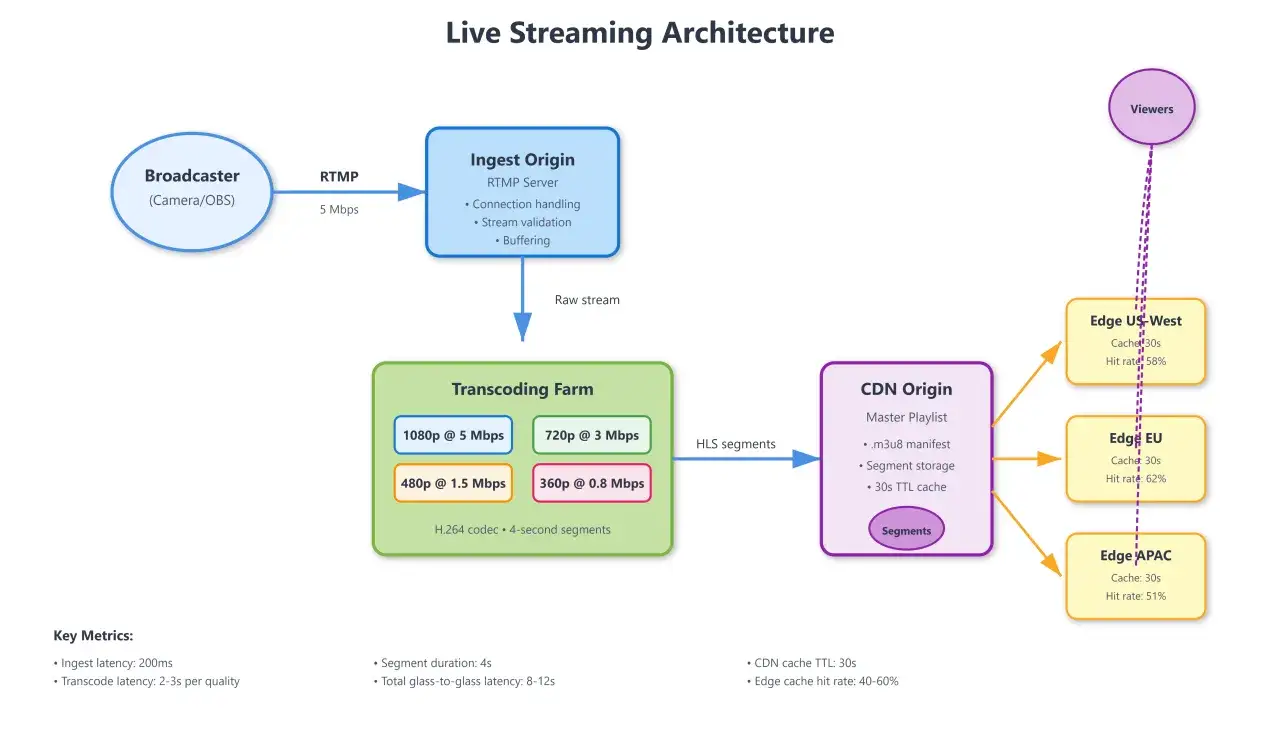
Where RTMP fits in a modern streaming stack
The first mistake I see is treating RTMP as the final delivery format. In practice, it is the transport between an encoder and the server, while viewers usually consume HLS or DASH. That split matters because it changes how you think about latency, compatibility, and where to spend your optimisation effort.RTMP still has a real job because it is simple for encoders to publish, reliable over TCP, and widely supported by streaming tools. The catch is that most browsers do not play it directly, so a server that only speaks RTMP is usually incomplete. If the audience needs browser playback, I would add packaging for HLS or DASH rather than trying to force RTMP to do everything.
| Protocol | Typical role | What it is good at | Where it falls short |
|---|---|---|---|
| RTMP | Encoder to server ingest | Simple publishing, low operational friction | Not a modern browser playback format |
| HLS | Viewer delivery | Broad device support, easy playback in browsers | Usually adds seconds of latency |
| DASH | Viewer delivery | Adaptive playback and good standards support | Less universal than HLS in some ecosystems |
| SRT | Contribution ingest | Better resilience on poor links | More setup work, less universal in consumer encoders |
That is why I usually design the server as an ingest-and-package layer, not as a single-purpose RTMP endpoint. Once that split is clear, the next decision is whether to install a package or build the stack yourself.
Choose the Linux deployment path that matches your workload
For most Debian and Ubuntu systems, the packaged NGINX module is the route I would choose first. It is easier to update, easier to remove, and much less annoying to maintain than a custom build. I only reach for a source build when I need a very specific patch set, a non-standard module combination, or a distro that does not ship the pieces I need.
| Route | Best for | Trade-off |
|---|---|---|
| Packaged module | Small to medium self-hosted servers | Least setup pain, but tied to your distro’s package version |
| Build from source | Custom tuning, older distributions, unusual module combinations | More control, more maintenance, more room for build mistakes |
| Managed platform | Teams that want less server administration | Higher recurring cost and less infrastructure control |
I also treat NGINX Plus as an enterprise option rather than a default. It supports the RTMP module as a dynamic component, but for a standard Linux VPS the open-source route is usually enough. My rule is simple: if the server only needs to ingest one or two live feeds, I keep the stack boring and minimise moving parts. That keeps the upgrade path clean when the stream becomes important enough to matter.
Build a basic NGINX RTMP server cleanly
A minimal setup is enough for a first working server. On a Debian-based machine, I would start by installing NGINX, the RTMP module, and FFmpeg for testing. FFmpeg is not mandatory for every workflow, but it is extremely useful when I want to push a test stream or verify that the server accepts the codec settings I plan to use.
Install the core packages
sudo apt update
sudo apt install nginx libnginx-mod-rtmp ffmpegOn some systems the module is loaded automatically after installation; on others, you may need to confirm that the vendor’s module include is active. The important part is not the exact packaging trick but the config layout: the RTMP block belongs at the top level, not buried inside the normal HTTP server block.
Use a minimal config first
rtmp {
server {
listen 1935;
chunk_size 4096;
application live {
live on;
record off;
hls on;
hls_path /var/www/hls;
hls_fragment 3s;
hls_playlist_length 12s;
}
}
}
http {
server {
listen 8080;
server_name _;
location /hls {
types {
application/vnd.apple.mpegurl m3u8;
video/mp2t ts;
}
root /var/www;
add_header Cache-Control no-cache;
add_header Access-Control-Allow-Origin *;
}
}
}Before reloading NGINX, I would create the HLS directory and make sure the web user can write to it:
sudo mkdir -p /var/www/hls
sudo chown -R www-data:www-data /var/www/hls
sudo nginx -t
sudo systemctl reload nginxThat configuration gives you a straight path: publishers connect on port 1935, and the server can expose HLS fragments over HTTP on port 8080. If you only need ingest, you can remove the HLS lines and keep the setup even lighter. With the server listening, the real test is whether an encoder can publish into it cleanly.
Publish a stream and verify it end to end
Once the server accepts connections, I test with both a live encoder and a file-based source. OBS Studio is convenient because it mirrors what real users will do, but FFmpeg is better when I want repeatable diagnostics. The point is to confirm three things: the app name matches the config, the codec is compatible, and the output path actually produces something the viewer can load.
Test from OBS or another encoder
For OBS, the server field usually looks like rtmp://your-server/live and the stream key becomes the stream name. If the application block is called live, the URL path must match that name. A mismatch there is one of the fastest ways to waste twenty minutes on an otherwise healthy server.
Push a file with FFmpeg
ffmpeg -re -i sample.mp4 \
-c:v libx264 -preset veryfast -pix_fmt yuv420p \
-c:a aac -b:a 128k \
-f flv rtmp://your-server/live/test-re makes FFmpeg read the file in real time instead of blasting it at full disk speed, and -f flv matches the container RTMP expects. I also like yuv420p because it avoids a class of compatibility issues that show up later on phones, browsers, or cheap playback clients.
Read Also: Online Video Explained - Smooth Streaming for 2026 & Beyond
Check the output the right way
If you enabled HLS, test the browser path from the HTTP side, not the RTMP URI. That distinction matters: the ingest connection and the playback URL are not the same thing. When the stream appears in VLC but not in a browser, the bug is usually in the packaging or HTTP serving layer, not in RTMP itself.
Once the publish path is stable, the remaining work is less about streaming and more about hardening the service so it stays stable when real traffic arrives.
Harden the server before the first real audience arrives
The most useful hardening step is also the dullest one: expose only the ports you actually need. If the box only ingests from one office or one cloud encoder, I would not leave port 1935 open to the whole internet. A VPN, an allowlist, or a private network segment is better than assuming no one will probe the service.
For viewer traffic, I prefer HTTP over HTTPS on a clean, narrow path. If the stream will be consumed in a browser, use TLS on 443 rather than inventing a side door on a random port. That keeps firewall rules easy to reason about and avoids surprises when networks block unusual outbound traffic.
- Open 1935/tcp only if the encoder really needs public access. Otherwise, keep it private.
- Use 80 or 443 for playback. Browsers and networks understand those ports better.
- Keep HLS fragments on writable storage with enough headroom. A 6 Mbps stream is about 2.7 GB per hour if you record it.
- Reserve bitrate margin. I aim for at least 30% headroom between sustained stream bitrate and real uplink capacity.
- Watch CPU only if you transcode. Relaying is cheap; live transcoding is what burns cycles.
Bandwidth planning deserves more respect than it usually gets. A 720p stream often sits around 3 to 5 Mbps, while a clean 1080p stream commonly needs 6 to 8 Mbps before overhead and spikes. On a modest connection, that means one extra stream can be the difference between smooth video and a frustrating cascade of buffering. Once the box is locked down, the remaining problems are usually small and mechanical.
The failures I would check first when a stream will not play
When live video breaks, the symptoms tend to repeat. I keep a short list in my head because it saves time and keeps the diagnosis boring. Most failures come from the same few places: the port is blocked, the app name does not match, the codec is wrong, or the server writes HLS fragments to a directory it cannot reach.
| Symptom | Likely cause | What I check first |
|---|---|---|
| Connection refused | NGINX is not listening or the firewall blocks 1935 |
ss -ltnp, ufw status, and nginx -t
|
| Publish succeeds but playback fails in browser | You are trying to play RTMP directly, or HLS is not being served | HTTP location for .m3u8 and .ts files |
| Bad name or rejected stream | The URL path does not match the application block |
Compare the encoder destination with the NGINX config |
| Black video or broken playback on mobile devices | Codec settings are too aggressive | Stick to H.264 video and AAC audio first |
| Lag or stutter under load | Bitrate is too high, uplink is saturated, or transcoding overloads CPU | Reduce bitrate, remove transcoding, or increase headroom |
| Empty HLS directory | Permissions or path mismatch | Check ownership of the HLS folder and the exact hls_path
|
When I can name the problem in one minute, I can usually fix it in five. That is the real advantage of keeping the setup simple: fewer hidden dependencies, fewer places for the stream to disappear, and much less pressure to invent a complicated theory before checking the obvious.
What I would keep in place after the first successful stream
If I were running a small live workflow today, I would keep one NGINX instance doing ingest, HLS packaging, and the minimum amount of access control needed to stay sane. I would not try to make RTMP satisfy every playback scenario, and I would not add transcoding until I had measured the actual bitrate, CPU, and disk profile of the stream.
For a growing setup, I would separate responsibilities before I upgraded hardware. One box for ingest, one for packaging or recording, and only then a second relay if geography or redundancy makes sense. That approach is usually cheaper than overbuilding the first server and cleaner than patching a fragile configuration after it has already gone live.
The simplest reliable pattern is still the one I trust most: H.264 and AAC on the encoder, port 1935 for ingest, HLS for viewers, TLS for public playback, and logs that I actually read when something changes. If those pieces are in place, a Linux streaming server stays predictable, which is exactly what you want when the stream matters.