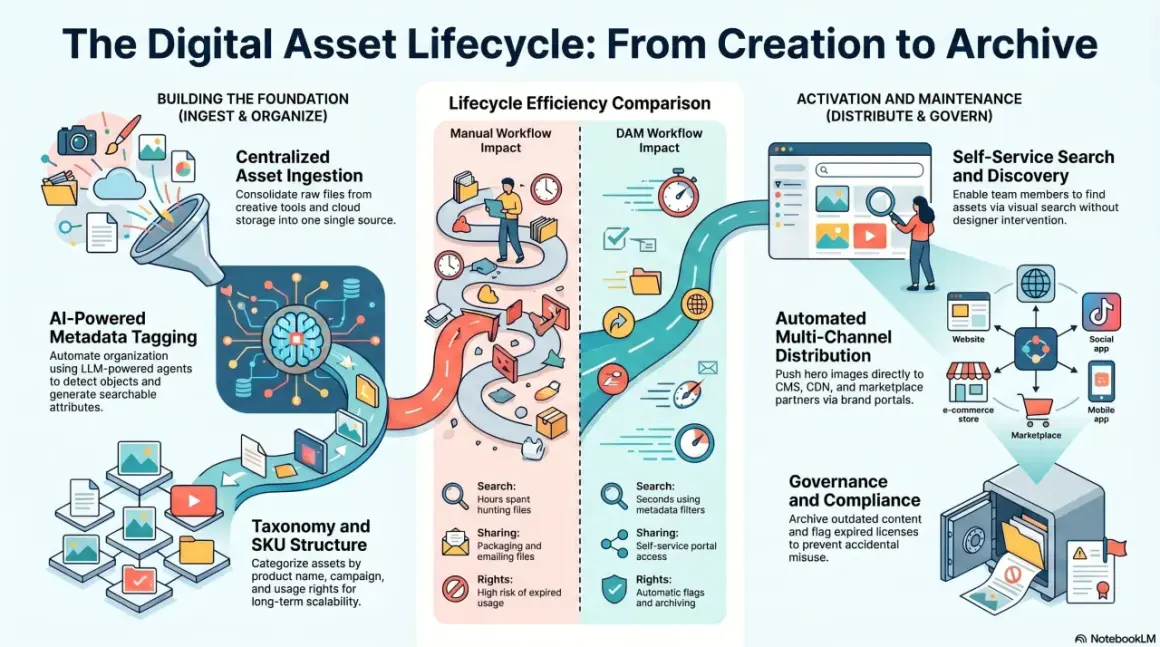
Digital asset creation works best when the production side and the management side are designed together. If a file cannot be named properly, tagged consistently, approved cleanly, and found again later, it becomes an expense rather than an asset. In this guide, I cover the workflow, metadata, UK rights checks, DAM features that matter, and the practical setup I would recommend for teams producing images, video, and audio.
The fastest way to make assets usable is to design for findability from day one
- Plan the workflow before you export the first file, especially if your team publishes to YouTube, social, or a website.
- Use metadata, naming rules, and a controlled taxonomy so search is reliable without folder digging.
- Choose a DAM when you need permissions, version history, reuse tracking, and external sharing in one place.
- Keep rights, licences, and approval records attached to the asset, not buried in email threads.
- Use AI for tagging and transcription, but keep a human in the loop for context and compliance.
Build the workflow before the library grows
Start with a simple flow: brief, create, review, approve, publish, archive. That sounds obvious, but most teams skip the discipline and end up with a chaotic mix of drafts, final cuts, thumbnails, subtitles, and social crops spread across different drives. I prefer to define the journey for each asset type before production starts, because video, image, and audio files rarely need the same checkpoints.
- Brief - define the channel, message, format, length, and owner.
- Create - work from named source files and templates so edits stay traceable.
- Review - collect comments in one place and keep the review version separate from the master.
- Approve - lock the final file, add metadata, and record the usage rights.
- Publish - export the right rendition for each channel, whether that is a YouTube thumbnail, a 16:9 edit, or a square social cut.
- Archive - move superseded versions into a controlled archive instead of deleting them.
The real value here is not process theatre; it is speed. When the workflow is clear, editors spend less time chasing approvals and more time improving the actual content. Once that path is stable, the next bottleneck is almost always findability, which is where metadata earns its keep.
Make metadata do the heavy lifting
Metadata turns a pile of files into a library. I usually separate it into three layers because each one solves a different problem: technical data helps the file render correctly, descriptive data helps people find it, and administrative data controls who can use it and under what terms.
| Metadata type | What it includes | Why it matters |
|---|---|---|
| Technical | Format, resolution, dimensions, file size, codec | Supports correct processing, transcoding, and quality checks |
| Descriptive | Title, caption, keywords, campaign, topic, speaker, location | Makes search and reuse far easier |
| Administrative | Owner, licence, permissions, expiry date, approval status | Reduces rights mistakes and access problems |
Folders still matter, but only as a storage layer. I treat them as the shelf, not the catalogue. Once that distinction is clear, the choice of platform becomes much easier to judge.
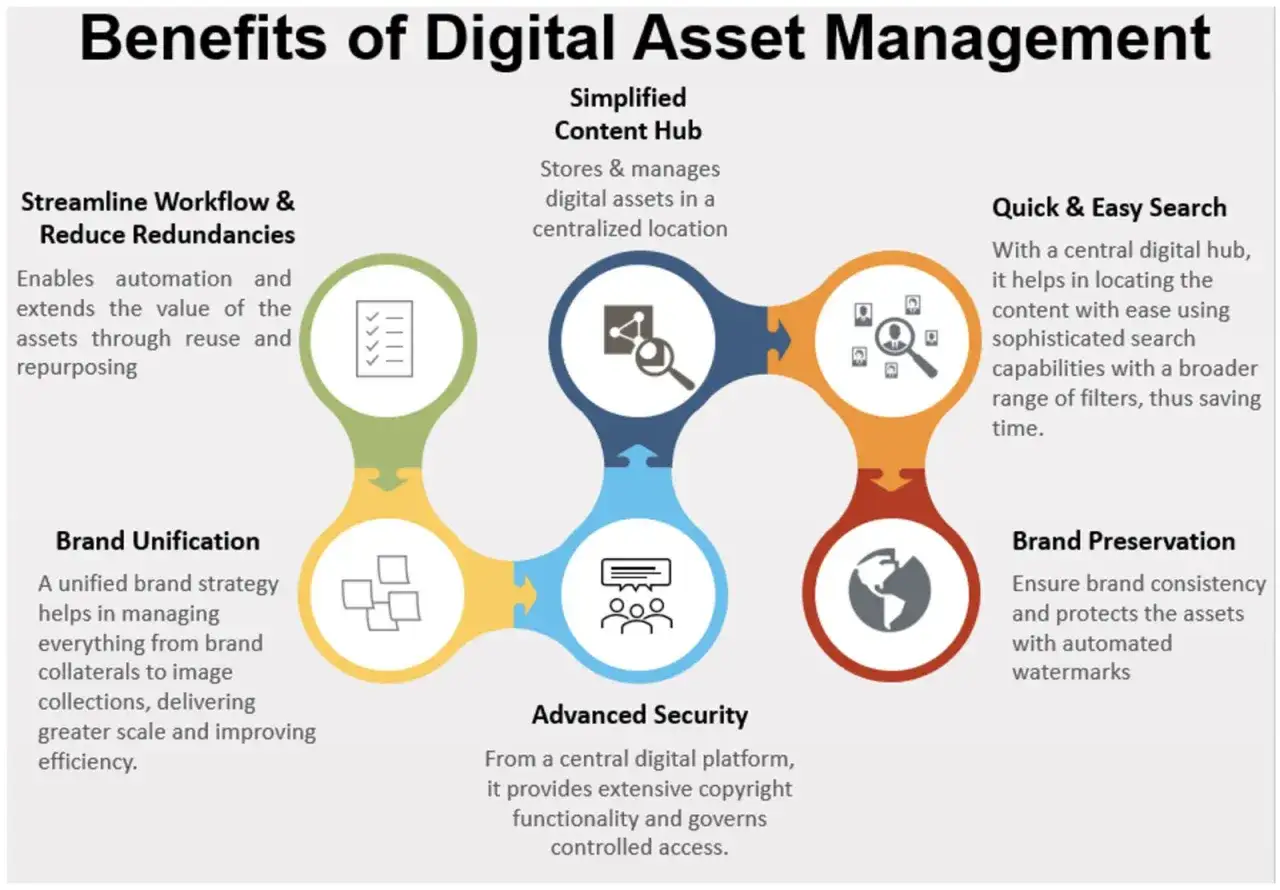
What a DAM should actually do for your team
A shared drive can store files, but it rarely governs them. A DAM does more: it indexes assets, controls access, tracks versions, records activity, and makes it possible to reuse one approved file across teams without losing the source of truth. On GOV.UK Digital Marketplace, I found examples that range from per-user annual pricing to instance-based monthly pricing, which is a useful reminder that DAM costs are driven more by workflow and scale than by the file storage itself.
| Option | Best for | Strength | Main limit | Typical cost pattern |
|---|---|---|---|---|
| Shared drive | Very small teams and short projects | Easy to use and already familiar | Poor search, weak permissions, and messy versioning | Usually bundled with existing office software |
| Basic cloud storage | Light collaboration and simple handoff | Quick sharing and low friction | Limited governance and weak asset discovery | Low subscription cost, often per user |
| DAM | Growing content teams and multi-channel publishing | Search, permissions, approvals, audit trail, and reuse | Needs setup, metadata discipline, and admin ownership | Examples can range from low per-user annual pricing to custom enterprise quotes |
What I look for is less about glossy interface and more about control. If the platform cannot separate masters from derivatives, enforce permissions, and expose clean metadata to other tools, it will not reduce friction for long. The better systems also support search faceting, which means users can filter by format, campaign, rights status, or channel instead of guessing filenames.
When the platform is doing its job, the next risk is no longer storage - it is compliance.
Rights, approvals, and UK compliance cannot be an afterthought
In the UK, copyright is not something you bolt on after publication. The Intellectual Property Office notes that images are generally protected as artistic works, so your DAM should store the licence, usage scope, expiry date, and any model or location releases alongside the file itself. That matters even more when one asset is reused across paid ads, organic social, web banners, and offline campaigns, because each channel can carry a different right to use.
- Keep release forms attached to the asset record, not in a separate folder.
- Record geographic and time limits on licences, especially for stock imagery and music.
- Flag personal data in metadata when filenames, captions, or transcripts include names or identifiers.
- Use role-based access so unfinished cuts or sensitive footage stay inside the right team.
- Keep audit logs for downloads and approvals if external agencies touch the library.
I would also treat retention as part of compliance, not housekeeping. If a campaign ended six months ago and the rights expired, the asset should move to an archived or restricted state rather than remain publicly searchable. That discipline becomes easier when the platform can enforce it for you, which is why AI features are useful only when the governance layer is already solid.
AI speeds up tagging, but it does not replace governance
AI is genuinely useful in asset production, but only for the parts of the job that are repetitive or pattern-based. Automatic transcription, object detection, scene recognition, OCR, and thumbnail generation can save real time, especially for video teams working with long-form footage and multiple edits. Where AI helps most is at the edges of the workflow: it can suggest tags, surface duplicate clips, and generate searchable text from spoken content.- Good use cases: subtitles, speech-to-text, first-pass tagging, duplicate detection, smart crops.
- Risky use cases: rights decisions, brand-sensitive naming, legal classification, or anything that depends on context.
- Human review is essential when a face, location, product variant, or campaign nuance matters.
My rule is simple: let AI accelerate the library, but never let it be the final authority. A transcript may be technically correct and still be useless if it misses speaker names; an image tag may be fast and still be wrong if it confuses a product prototype with the approved launch version. The point of automation is to make the team more accurate and faster, not to turn every asset into an unverified guess.
The last step is to pull all of this into a system that a real team can maintain without heroics.
What I would lock down before the library starts to scale
If I were setting up a content operation for a small or mid-size UK team, I would keep the first version of the system boring on purpose. The goal is not maximum complexity; it is consistency that survives busy weeks, agency handoffs, and last-minute publishing requests.
- Define one owner for the library. If nobody owns the rules, the rules drift.
- Limit mandatory metadata to 8-12 fields. Enough to search, rights-check, and route approvals, but not so many that people ignore the schema.
- Use one controlled tag list for the terms the team actually uses. This is where taxonomy beats improvisation.
- Separate working, review, approved, and archived states. A single bucket for everything is where mistakes hide.
- Require version notes on every new upload. When a clip changes, the reason should be visible without digging through email.
- Measure three things every month: time to find an asset, reuse rate, and approval turnaround. If search regularly takes more than a minute, the structure is too loose.
That setup is not glamorous, but it is durable. Once you can find, trust, and reuse an asset quickly, the library stops behaving like storage and starts behaving like a production system. That is the point where content teams feel the benefit in every campaign, every edit, and every repurposed cut.