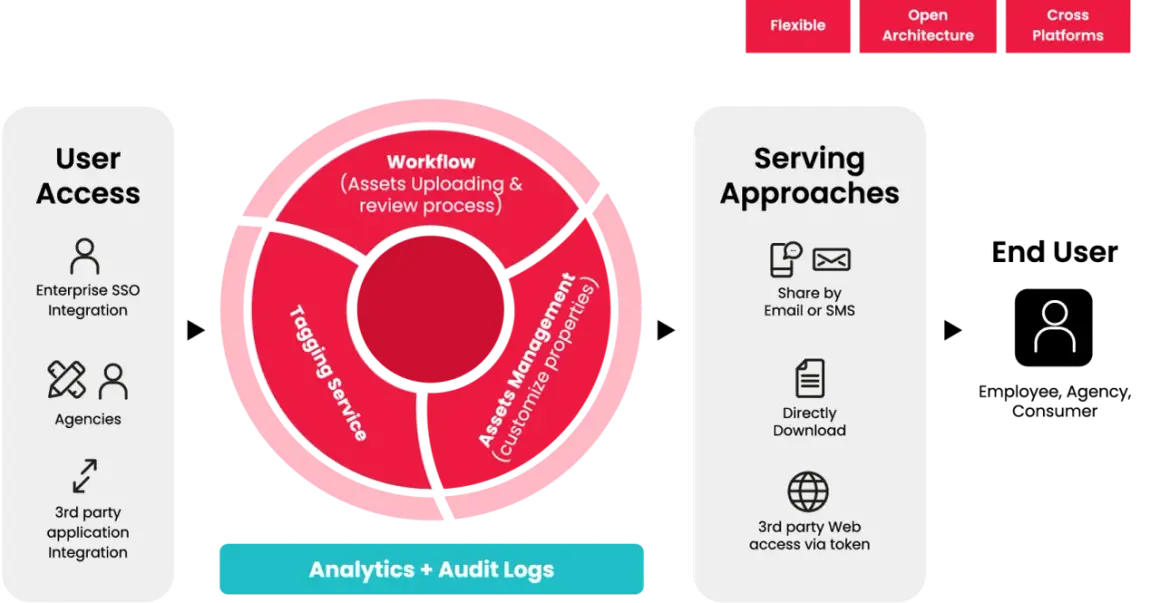
Managing digital files well is less about storage and more about moving the right version from capture to approval to delivery without losing track of rights, context, or quality. A strong digital asset management workflow gives that path structure, so teams can publish faster, reuse more, and avoid the usual chaos of duplicate files, broken naming, and last-minute format fixes. For video-heavy teams, this matters even more because one shoot often produces masters, cut-downs, thumbnails, captions, and channel-specific versions.
The most useful parts of the process are the ones that keep assets searchable, approved, and ready to publish
- DAM is not just storage; it is the rules, roles, and automation that move assets through creation, review, publishing, and archive.
- The workflow starts with ingestion and metadata, not with folder cleanup.
- Video teams need stronger version control and more derivative formats than static creative teams.
- Keep mandatory metadata lean or people will work around the system.
- Measure success by time to publish, search success, reuse, and fewer compliance problems.
- In the UK, rights, consent, and retention should be built into the process from day one.
What a modern DAM workflow actually covers
When I map a DAM setup, I treat it as an operating model, not a storage product. It combines metadata, permissions, review gates, version control, automation, and distribution rules so assets can move from rough material to approved content without confusion.
The important distinction is simple: a folder system helps you store files, but a workflow helps people make decisions. That means the library should answer practical questions at every stage, such as who owns the asset, what it can be used for, which version is current, and when it should expire. For media teams, that is the difference between a searchable source of truth and a shared drive with a nicer interface.
I also find that the best setups do not try to automate everything. They automate the repetitive parts, then leave room for human judgement where brand, legal, or editorial risk is real. Once that balance is clear, the rest of the pipeline becomes much easier to design.
That leads naturally to the actual asset path, because the workflow only works if each stage has a clear job.

The path from capture to approval
Ingest and preflight the source material
The first job is to get the right files into the system without damaging the source. I would preflight each upload for file integrity, naming, resolution, codec, audio quality, and duplicates before anything is marked usable. For video, this is where you separate masters, proxies, project files, and exports so nobody edits the wrong version later.
Preflight sounds basic, but it prevents a surprising amount of rework. A missing audio track, wrong frame rate, or corrupted upload can waste hours if the issue is discovered after review has already started.
Describe the asset so people can find it later
Metadata is the descriptive layer that tells the library what the file is, who created it, where it belongs, and how it may be used. Good metadata usually includes title, campaign, shoot date, owner, channel, language, rights, expiry date, and a controlled set of tags.
If you work with video, I would add captions, transcripts, and aspect-ratio notes whenever possible. Those details improve search, support accessibility, and make it much easier to create channel-ready edits without guessing.
Route it through review and approval
This is where many teams slow themselves down. A clean approval process should make it obvious who can comment, who can approve, and who can publish. I would keep the approval chain short for routine content and stricter for regulated or high-value assets.
In practice, the biggest mistake is letting feedback, approval, and publication blur together. If those roles are not separate, version history gets messy and no one is certain which file is actually live. That is especially painful when one campaign has to be adapted for YouTube, social, and paid placements at once.
Once the file is approved, the workflow should move into format control and delivery, because that is where the library either stays reliable or starts producing duplicates.
How assets get formatted, distributed, and retired
Generate the right renditions for each channel
A rendition is simply a transformed version of the same source asset, such as a compressed preview, a square social cut, a vertical short, or a thumbnail. Good DAM systems create these automatically so the team does not keep exporting the same content by hand.
This step matters most for video optimisation. A single master can become several delivery-ready versions, each with a different resolution, aspect ratio, bitrate, or caption file. If the workflow is set up properly, those outputs appear as controlled variants instead of random copies.
Distribute only the approved version
Once an asset is approved, it should move to the places where people actually use it: a CMS, a social publishing tool, a partner portal, an ad platform, or an internal library. The rule I use is simple: the published file should be traceable back to its source, and the source should remain untouched.
That traceability becomes even more important when teams are working across markets. A distributor in one region may need the same creative, but with different text, subtitles, music rights, or expiry dates. The workflow should make those differences explicit instead of hiding them in file names.
Read Also: Video Library Manager: Build a Usable Archive That Works
Archive and retire the asset cleanly
Good archiving protects the future. It keeps the master file, records what was approved, and marks outdated or expired versions so they are not reused by mistake. If an asset has licence restrictions, talent limits, or a campaign end date, that information should drive the archive rule, not memory.
This is where a lot of libraries become trustworthy or untrustworthy. If expired assets keep resurfacing, people stop relying on the system and start keeping private copies. That is usually the moment a DAM starts behaving like a risk, not a solution.
Once the path is clear, the next question is not about storage at all. It is about whether the right people can find and trust the content they need.
Why metadata and rights management decide whether people trust the library
I rarely see a DAM succeed when metadata is treated as an afterthought. Searchability depends on it, reuse depends on it, and governance depends on it. If the schema is vague, users stop trusting search and fall back to local folders, email attachments, or chat messages.
The trick is to design a taxonomy that reflects how people actually search, not how the organisation is structured. Someone looking for a campaign video usually thinks in terms of product, audience, format, and channel. They do not think in terms of departmental silos. A useful taxonomy mirrors those real-world questions.
| Metadata field | Why it matters | What goes wrong without it |
|---|---|---|
| Owner | Shows who is accountable for updates and approvals | No one knows who can fix a mistake |
| Usage rights | Defines where and how the asset may be used | Content gets published outside its licence window |
| Expiry date | Tells the system when an asset should be retired | Old creative keeps resurfacing in new campaigns |
| Channel | Helps the team pick the right format quickly | People export the same file repeatedly by hand |
| Language or territory | Prevents cross-market mix-ups | Regional teams publish the wrong version |
Rights management deserves the same seriousness. If your content includes talent, music, location footage, or third-party brand material, the file should carry enough information to show where it can run, for how long, and in which markets. In the UK, I would treat consent records, retention rules, and licence windows as first-class metadata rather than legal paperwork stored elsewhere.
In 2026, AI-assisted tagging can help with volume, but it does not replace a controlled vocabulary. I would use automation to suggest tags, not to invent the meaning of the asset. That keeps the library fast without making it sloppy.
With the information layer in place, the next step is making the process fit the way real teams work instead of forcing people to adapt to the software.
How to design a workflow that your team will actually use
I usually start by mapping three things: asset types, decision points, and people. A short workflow for a social cut-down looks very different from the route for a flagship brand film, and the system should reflect that difference rather than pretending all content deserves the same path.
Here is the practical structure I prefer when a team is building or cleaning up a content pipeline.
| Asset type | What to capture on ingest | Approval focus | Best distribution pattern |
|---|---|---|---|
| Raw footage | Project ID, shoot date, camera source, rights notes | Technical quality and consent | Internal use only |
| Edited video | Version number, duration, language, aspect ratio | Brand accuracy and narrative fit | CMS, YouTube, social, paid media |
| Thumbnail or still | Campaign, size, variant label, usage window | Clarity and visual consistency | Channel-specific publishing |
| Evergreen library asset | Topic, owner, review date, expiry date | Freshness and reuse potential | Searchable internal library |
The main design choice is where to use automation and where to keep a manual gate. I would automate repetitive tasks such as file naming, derivative creation, notifications, and expiry alerts. I would keep manual review for anything that changes meaning, carries legal risk, or affects brand trust.
It also helps to define service levels. Routine content should not sit in review for days without a reason. In my experience, a healthy process has a small number of approval rounds, a clear escalation path, and a shared expectation for turnaround times. If you need four or five rounds for every asset, the issue is usually the process, not the people.
One more rule matters here: do not build the workflow around exceptions. Design for the 80 percent case first, then document the edge cases separately. That keeps the system usable for the team that has to live in it every day.
Even with a good design, there are a few failure modes that show up again and again, and they are worth naming directly.
The mistakes that quietly break DAM adoption
The most common mistake is turning the DAM into a prettier file cabinet. If people still have to guess which version is current, manually rename files, or ask around for approval, the system has not solved the real problem.
Another weak spot is overbuilding metadata. A schema with too many mandatory fields looks disciplined at first, but it usually slows uploads and produces bad entries because people rush through the forms. I would rather have a smaller set of accurate fields than a long checklist full of junk.
- Too many approval stages, which creates bottlenecks and pushes teams back to email.
- No version discipline, which makes it impossible to tell draft from final.
- Folders that mirror politics instead of search behaviour.
- No expiry or archive rules, which lets outdated assets keep circulating.
- Permissions that are too open, which raises compliance risk.
- No onboarding or training, which leaves the DAM underused.
I also see teams underestimate the cost of migration. Moving old content into a DAM without cleaning names, rights data, and duplicates usually just relocates the mess. If the library is going to become a source of truth, the move has to be selective, not mechanical.
For UK organisations, the risk is not only inefficiency. It is also the possibility of retaining content longer than needed, publishing with outdated consent, or using assets outside their rights window. Those problems are much easier to prevent at the workflow stage than to fix after publication.
Once those traps are visible, the last piece is knowing whether the process is actually improving instead of merely looking organised.
The numbers I would watch after launch
I would not judge a DAM by how tidy it looks on day one. I would judge it by how quickly people can find assets, how often they reuse approved content, and how few surprises appear during publishing. Those signals tell you whether the workflow is helping the business or just making the library more formal.
| Metric | What it tells you | What to look for |
|---|---|---|
| Time to first publish | How long it takes to move from upload to approved use | Shorter is better, especially for routine content |
| Average approval rounds | Whether review is lean or clogged | Keep it low for standard assets |
| Search success rate | How often users find the right asset without help | Rising success means the taxonomy is working |
| Reuse rate | Whether teams trust the library enough to repurpose assets | More reuse usually means stronger governance |
| Expired asset incidents | How often outdated files are used by mistake | Should trend towards zero |
| Complete metadata rate | How consistently teams fill in the fields that matter | High consistency is better than elaborate tagging |
I would review those numbers monthly, not once a year. That cadence is quick enough to spot friction, but not so frequent that the team spends all its time reacting to noise. If a metric is bad, I would first ask whether the process is unclear, the fields are burdensome, or the team simply was not trained well enough.
The cleanest DAM setups are the ones that keep the rules simple and the consequences visible. If you make the workflow easy to follow, assets move faster, teams reuse more, and the library gradually becomes a place people trust instead of a place they avoid.
The controls I would lock in before scaling further
If I were tightening a workflow before rolling it out across more teams, I would start with three controls: a short metadata standard, a simple approval matrix, and an expiry rule for every asset with a time limit. Those three choices remove more friction than most software features.
I would also standardise naming conventions, thumbnail previews, and a single place for comments so feedback does not scatter across email threads. The point is not perfection. The point is to make the system predictable enough that people use it without thinking twice.
Once those basics are in place, the rest becomes easier to scale: more channels, more contributors, more regions, and more content types. That is when a DAM stops being a repository and starts acting like part of the production line itself.