
A WebRTC phone gives you browser-based voice and video calling without forcing people to install a native client. For streaming and live video teams, that matters because the same real-time stack can power host interviews, backstage comms, guest support, and fast-turn remote production. In 2026, the real decision is not whether the technology works, but where it fits best in the wider production chain.
The core trade-offs behind browser-based calling and live video
- WebRTC is the transport layer, not the whole product. You still need signaling, media routing, and usually a provider or server stack.
- Direct peer-to-peer works well for small sessions. Once you move beyond 2-3 interactive peers, a server-based design is usually the safer choice.
- STUN and TURN are not optional details. They decide whether calls connect reliably across home networks, offices, and mobile data.
- For live video, WebRTC is usually the contribution path. Large audiences are better served by a broadcast layer such as HLS or a similar delivery pipeline.
- UK rollouts need practical checks. Confirm PSTN reach, browser mix, firewall behavior, and where media traffic is routed.
What a WebRTC phone really is
At its simplest, a WebRTC phone is a calling endpoint that runs in a browser, desktop app, or mobile shell and uses WebRTC to move audio and video in real time. It is not a physical desk phone, and it is not just a softphone with a new label. The important shift is that the user interface lives where the work already happens: in the browser, the studio dashboard, the support console, or the live production tool.
That also means the stack is split into parts. WebRTC handles media transport and encryption, but the app still needs signaling to exchange connection details, plus some way to get through firewalls and NAT. In plain English: one system says, “I am here, here is how to reach me,” and another system makes sure the actual media path can survive messy real-world networks.
I usually treat this as the first design decision, because it changes everything downstream. If you only need a private browser call, the stack can stay lean. If you need to bridge to SIP or the public phone network, the architecture becomes more like telephony with a real-time front end. That distinction leads directly into where the technology helps most in streaming and live video.
Why it matters for streaming and live video
For live production, the value is not “video calling” in the abstract. The value is low-latency interaction at the exact points where production teams lose time: guest intake, remote contributor feeds, producer talkback, moderation, and last-mile communication between host and control room. I see WebRTC work best when the workflow needs human response, not just distribution.
Typical use cases include:
- Remote guest interviews for livestreams, podcasts, and creator shows.
- Backstage communication between a presenter and a producer during a live event.
- Call-in segments where viewers join from a browser instead of a separate app.
- Low-latency contribution from remote locations when a full studio setup is not available.
- Hybrid production tools that combine live video, audio routing, and quick handoff to recording or transcription.
The limit is just as important. If your main job is to deliver a large audience stream, WebRTC is usually not the final delivery format. It is better suited to the interactive layer that feeds the show, while the audience watches through a broadcast-friendly pipeline. That is the cleanest mental model before you start thinking about architecture.
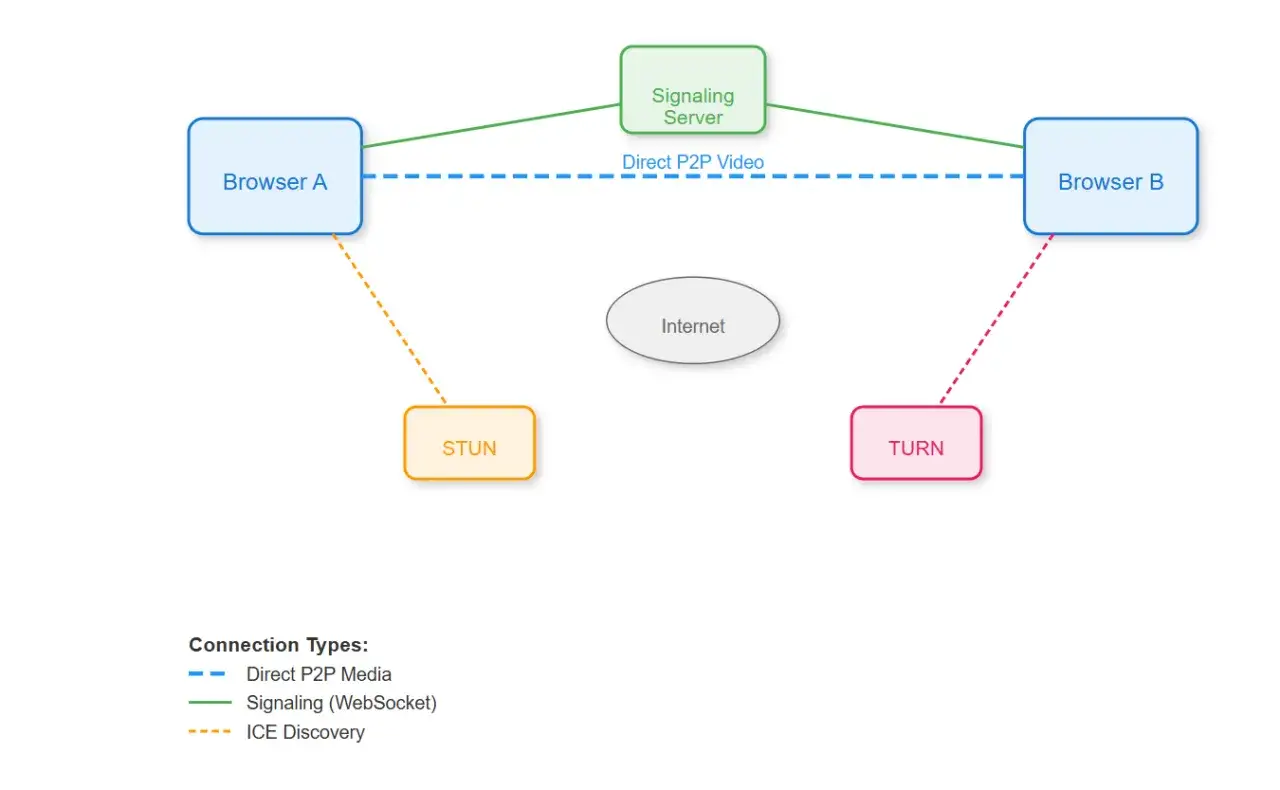
How the audio and video path actually works
When people say “it just works,” they usually skip the part that makes it work. The browser first exchanges connection details through signaling. Then the endpoints use ICE to test possible network paths. A STUN server helps a device discover how it appears from the outside, while a TURN server relays media when direct connection attempts fail. That fallback matters more than most teams expect.
WebRTC.org separates peer connection from signaling for a reason: the media engine does not magically know where the other party lives. It needs an out-of-band exchange, usually over HTTPS or another API layer. Once the peers have enough information, the call can lock onto the best available route and negotiate codecs, encryption, and packet flow.
In practice, I watch for three things:
- Network path quality. Corporate firewalls, CGNAT, and restrictive Wi-Fi can break otherwise healthy calls.
- TURN availability. If your fallback path is weak, support tickets appear quickly and without much warning.
- Media security. The stack should encrypt voice and video by default, not as an optional upgrade.
Once that path is clear, the next question is whether you should run the call directly between participants or insert a server in the middle.
Choosing the right architecture for your use case
For small internal sessions, direct peer-to-peer is attractive because it keeps moving parts to a minimum. For anything that involves multiple guests, mixed devices, or a production team, I usually prefer a server-based design. The difference is not academic; it changes latency, reliability, cost, and how much control you have over the session.
| Architecture | Best for | Strengths | Main trade-off |
|---|---|---|---|
| Direct peer-to-peer | Two-person interviews, quick guest checks, ad hoc calls | Simple setup, low latency, fewer server dependencies | Comfortable for 2-3 participants, but scaling gets awkward fast |
| Browser to SIP or PSTN bridge | Call-ins, legacy telephony, studio lines, contact workflows | Reaches standard phone numbers and SIP estates without forcing a native app | More integration points and carrier dependencies |
| SFU-based real-time session | Roundtables, panel shows, backstage comms, multi-guest live video | One sender can feed many receivers efficiently, with better control over media flow | Needs proper server sizing and orchestration |
| WebRTC into a broadcast pipeline | Large audiences, live events, creator broadcasts, OTT-style delivery | Keeps contribution interactive while the audience side scales more cleanly | The audience no longer receives fully interactive media end to end |
The rule of thumb I use is blunt but useful: if more than 2-3 people need to speak or exchange video at once, I stop thinking in pure peer-to-peer terms. That does not mean P2P is bad; it means the job has moved into production territory, and production needs a server model that can absorb real-world instability. That leads neatly into rollout details, especially for UK teams.
What I would check before rolling it out in the UK
UK deployments have the same technical problems as anywhere else, but the failure modes show up in slightly different combinations: mixed browser support, office firewall rules, mobile-heavy use, and a healthy amount of hybrid telephony. Before I launch anything live, I want the calling path tested on real devices, in real networks, under real pressure.
- Number reach and handoff. If you need to touch the public phone network, confirm that the platform can handle UK landlines and mobiles in the way your workflow expects.
- Browser mix. Test Chrome, Edge, Safari, and the mobile browsers your audience or guests actually use.
- Firewall resilience. Make sure the call still connects when UDP is restricted and TURN has to take over.
- Media routing. Keep an eye on where audio and video are processed so remote guests do not get routed through an unnecessarily distant region.
- Recording and transcription. If the stream needs captions, archives, or searchable logs, wire that into the workflow early rather than bolting it on later.
- Operator visibility. Give producers and support staff clear call states, join errors, jitter indicators, and fallback status.
- Consent and clarity. Show when recording is active and make the call state obvious to users who are joining mid-session.
I also like to test one locked-down corporate network and one weaker mobile connection before signing off. If it survives those two environments, it is usually honest about its strengths and limits. From there, the next thing to watch is the set of mistakes that quietly ruin call quality even when the technology is fine.
Common mistakes that hurt call quality
Most bad real-time experiences are not caused by WebRTC itself. They come from unrealistic assumptions about networks, device quality, or how many people should be interactive at once. The stack gets blamed because it is visible, but the real failure often happened one layer earlier.
- Skipping TURN. A call that works in the office may collapse in the wild if there is no proper fallback relay.
- Testing only on perfect Wi-Fi. Home broadband, hotel networks, and mobile data expose different failure modes.
- Using the same design for a private interview and a public event. Those are different problems and should not share the same architecture by default.
- Ignoring audio hardware. Cheap microphones, echo-prone rooms, and headset discipline matter more than many teams admit.
- Underestimating observability. If you cannot see packet loss, failed joins, or reconnect loops, you will only learn about the issue after users complain.
- Forgetting the production workflow. A stable call is only half the job if the guest still cannot be brought cleanly into the show, recorded, or handed off to a moderator.
My strongest opinion here is simple: audio quality is usually the first thing people forgive in a demo and the first thing they remember in production. That is why the final choice should be based on operational fit, not just on whether the demo feels smooth.
The decision rule I use when the brief is still fuzzy
If the job is a quick one-to-one conversation, I start with browser-first calling. If the workflow must touch SIP or the public telephone network, I bridge it rather than replacing everything around it. If the session is truly live and multi-party, I add an SFU instead of hoping peer-to-peer will stay stable under load. And if the audience is large, I keep WebRTC on the contribution side and let a broadcast layer handle distribution.
That split keeps the system honest: real-time where interaction matters, scalable delivery where reach matters. For streaming and live video teams, that is usually the difference between a nice prototype and a setup that survives a real show, a real audience, and a real production deadline.