The essentials at a glance
- Searchable metadata matters more than raw storage once a library starts growing.
- AI tagging helps, but clean naming rules and controlled fields still do the heavy lifting.
- Small teams can often begin with a lightweight media library; larger teams usually need DAM or MAM features.
- Version control, permissions, and rights data prevent the most expensive mistakes.
- A library with 500 clips needs a very different structure from one with 50,000.
What a useful system does for a growing library
In practice, a good video asset system does five jobs at once: it stores the master files, creates previews or proxies, attaches searchable metadata, controls who can see what, and tracks versions. I prefer to think of it as the operating layer above storage. The files can live on a NAS, cloud bucket, or hybrid setup, but without indexing and rules, the library remains just a pile of media.
- Searchable indexing turns filenames and tags into retrieval.
- Proxy playback lets people review large files without downloading the master.
- Version tracking keeps finals, drafts, and exports from colliding.
- Access control stops unreleased footage from being shared casually.
- Export and transcode workflows reduce manual conversion.
The features that matter most in 2026
In 2026, the useful platforms are the ones that combine structure, search, and governance instead of simply offering more disk space. AI-assisted tagging is helpful, but only when it sits on top of a clean metadata model. If the tags are messy, the automation just helps you make a mess faster.
| Feature | Why it matters | What good looks like |
|---|---|---|
| Metadata templates | They keep every upload consistent and searchable. | Required fields for project, date, rights, and asset type. |
| AI-assisted tagging | It speeds up first-pass organisation on large libraries. | Suggested tags that can be edited before publishing. |
| Advanced search and filters | They let teams find clips by date, topic, format, or usage rights. | Fast filtering that narrows results in a few clicks. |
| Proxy playback and thumbnails | They make review possible without moving giant master files around. | Smooth browsing of footage on desktop and mobile. |
| Version control | It prevents overwritten finals and duplicate exports. | A clear chain from working draft to approved version. |
| Permissions and sharing | They protect unreleased material and client-only content. | Role-based access with secure links and expiry dates. |
| Transcoding and export presets | They remove repetitive format conversion. | Common delivery formats generated automatically. |
| Audit trail | It shows who changed, shared, or approved an asset. | Clear activity history for compliance and accountability. |
The systems that save the most time are usually not the flashiest; they are the ones that reduce human interpretation at the moment of retrieval. Once those basics are in place, structure becomes the next bottleneck, because search only works if the library itself is organised in a way people can trust.
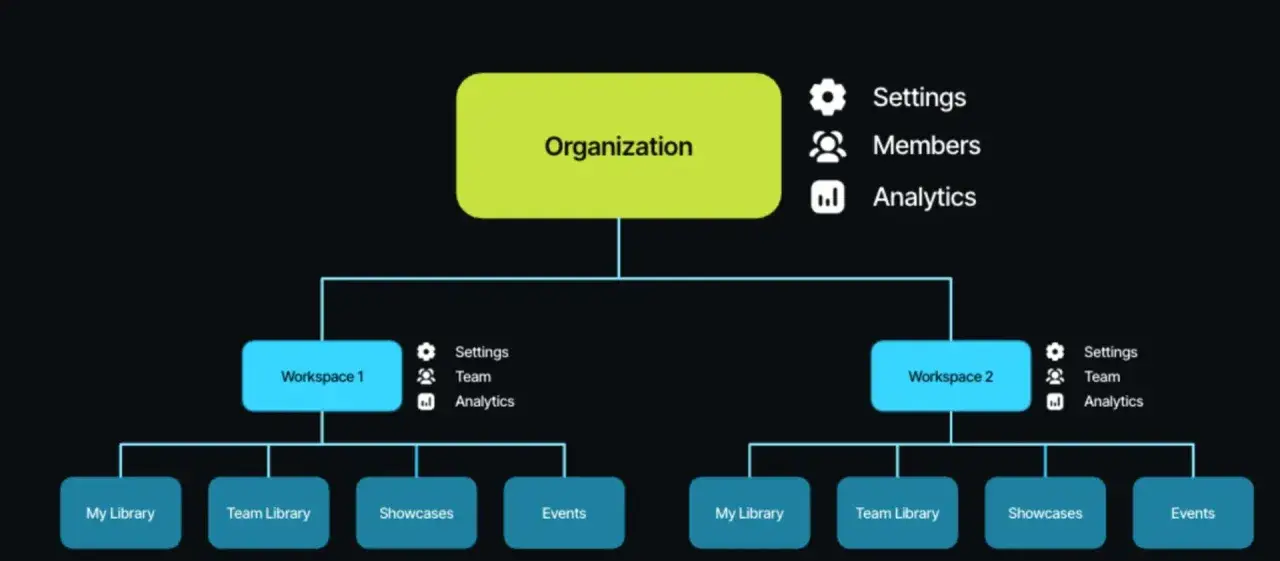
How to structure the archive so search works
I usually treat metadata as the product, not the garnish. If the archive is built for browsing, people will keep browsing. If it is built for search, they will find what they need quickly and stop duplicating work. For that reason, I keep the first layer of taxonomy small and predictable: project, asset type, status, and rights are usually enough to start.
| Field | Why I use it | Example |
|---|---|---|
| Project or campaign | It gives every file a clear home. | Spring launch 2026 |
| Shoot date | It helps sort rushes, interviews, and revisions. | 2026-05-14 |
| Asset type | It separates masters, proxies, exports, and social cuts. | Master / proxy / final export |
| Rights status | It protects you from accidental reuse. | Cleared until 2027-03-31 |
| Language or locale | It matters when subtitles or regional versions exist. | English UK |
| People or location | It speeds up footage-heavy searches. | Bristol studio, interview with client lead |
- Keep folder depth to three levels max unless the team has a strong reason to go deeper.
- Use dropdown lists or controlled vocabularies instead of free-text tags wherever possible.
- Put version numbers in metadata as well as filenames, so the approved file is obvious.
- Separate masters from exports, and never mix them in the same working folder.
That structure pays off only if the team uses it consistently, which is why the choice of platform matters next. A good taxonomy in the wrong tool still becomes frustrating once the archive grows beyond a few hundred files.
Choosing the right class of tool
Not every archive needs enterprise software. If you are a solo creator or a small agency with a few hundred clips, a lean media library may be enough. Once you need approvals, rights tracking, and cross-team access, DAM starts to make sense; once you are handling rushes, proxies, and heavy post-production hand-offs, MAM becomes the better fit.
| Option | Best for | Strengths | Limits | Typical fit |
|---|---|---|---|---|
| Lightweight media library | Solo creators and small teams under about 1,000 clips | Quick setup, simple browsing, low overhead | Weak governance and limited workflow control | Basic archive and easy sharing |
| DAM | Marketing, brand, and content teams with thousands of assets | Metadata, permissions, approvals, search, sharing | Can feel broad if the team only needs editing support | Campaign libraries and central brand control |
| MAM | Production, broadcast, and post teams moving large video files | Ingest, proxies, transcoding, editorial workflows | More complex and usually more expensive to run | Raw footage, rushes, and multi-stage production |
My rule of thumb is simple: under roughly 1,000 assets, keep the system light; between 1,000 and 10,000, metadata discipline becomes non-negotiable; above that, search automation and governance stop being optional. Picking the right class of platform is only half the job, because rollout is what decides whether people actually use it.
How I would roll it out in a real team
The cleanest implementation is the one that starts small and gets boring quickly. I would not migrate an entire archive in one hit unless the existing library is already tidy. In most teams, the fastest route is to test the structure on one project, fix the weak points, then expand.
- Audit the current archive by counting clips, identifying duplicates, and separating masters from exports.
- Define the first taxonomy with no more than 20 to 30 fields, because more than that usually causes inconsistent tagging.
- Pilot on one project or a sample of 200 to 500 assets so you can see where people hesitate.
- Migrate in batches instead of moving everything at once, which keeps mistakes contained.
- Train the team with a short session on search, versioning, naming, and rights handling.
- Assign ownership so one person maintains taxonomy and one person oversees retention and cleanup.
For a messy archive with more than 10,000 assets, I would expect the audit and migration to take several weeks, not a weekend. For UK teams, I would also bring rights expiry and retention review into the first migration, because those fields are far easier to enforce when they are part of the system from day one. Once the rollout is stable, the real challenge shifts to avoiding the habits that quietly break the archive later.
The mistakes that quietly ruin a video library
Most broken libraries do not fail because the software is bad. They fail because the team treats the software like a filing cabinet instead of a working system. The issues are predictable, and I see the same ones again and again.
- Using folders as the only organising layer leaves search weak and inconsistent.
- Mixing masters, proxies, exports, and social versions makes approval and reuse messy.
- Letting everyone invent their own tags destroys consistency within months.
- Over-tagging every file slows uploads and usually produces fields nobody trusts.
- Ignoring rights and consent data creates legal risk when footage is reused later.
- Skipping cleanup lets duplicates and obsolete versions pile up until search becomes noisy.
A good test is this: if the team can no longer tell which file is current without opening three versions, the archive is already drifting. The final piece is maintenance, because a library only stays useful if someone keeps it honest.
The setup choices that keep paying off after launch
The long-term winners are rarely the teams with the most advanced tooling. They are the teams that keep a few rules consistent: a short taxonomy, clear ownership, regular rights checks, and a predictable review cycle. That is enough to stop the library from decaying into a pile of almost-identical files.
- Review the top-level taxonomy quarterly and remove fields nobody uses.
- Check permissions and shared links monthly if multiple clients or external partners are involved.
- Archive stale projects after about 90 days if they are no longer active.
- Measure search success: if people cannot find a clip in under 10 seconds, the metadata model needs work.
- Keep one release checklist for final exports so approved files are always easy to identify.
If I were starting from scratch, I would spend less time chasing the perfect platform and more time getting metadata, ownership, and review rules right. The software can change later; the habits are what keep the archive useful.