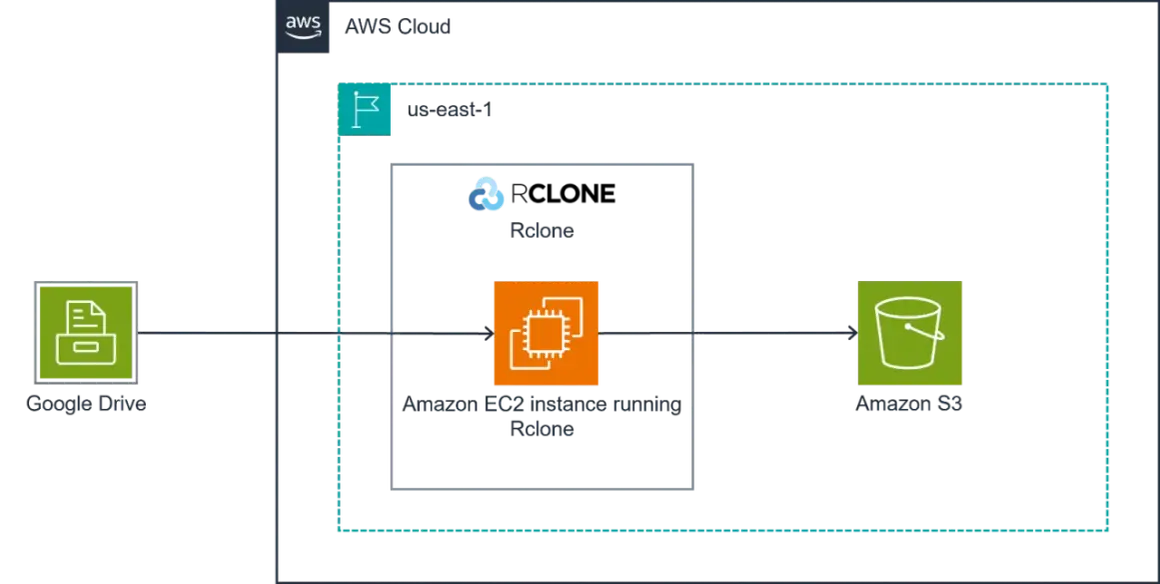
A Google Drive to S3 move is rarely just a storage swap. It changes how you handle access, naming, exports, file recovery, and long-term cost. In this article I break down the migration choices, the safest transfer workflow, and the details that matter most when the library includes video masters, graphics, or Google Docs that need exporting first.
What matters before you move anything
- S3 is the better fit when you want scalable object storage, automation, and predictable archive control.
- Browser-based downloads and uploads are fine for tiny jobs, but they become fragile once folders, retries, and mixed file types enter the picture.
- For most serious transfers, I would use a scripted bridge on a cloud machine rather than moving data from a laptop.
- Google Docs, Sheets, and Slides need export formats before they become usable objects in S3.
- S3 Standard is the safest landing zone; colder content can move into Intelligent-Tiering or infrequent-access classes later.
- Permissions and version history do not map cleanly from Drive to S3, so verification is part of the migration, not an optional extra.
Why this migration is different from a simple file copy
Google Drive and Amazon S3 solve different problems. Drive is built around collaboration: shared folders, comments, editable documents, and a user-facing interface. S3 is an object store, which means the useful units are buckets, keys, prefixes, and policies rather than shared links and document threads. That distinction matters because a migration is not just about moving bytes; it is about changing the operating model of the content.| Storage model | What it is good at | What usually changes in the move |
|---|---|---|
| Google Drive | Team collaboration, lightweight sharing, editable documents | Native Docs files, comments, and sharing behaviour need special handling |
| Amazon S3 | Durable object storage, automation, lifecycle management, media delivery | Folders become prefixes, access becomes bucket policy or IAM, and archives can be tiered by access pattern |
That shift is why I never treat this as a drag-and-drop exercise. I treat it as a storage design decision first, and a file transfer second. Once that mindset is in place, the next question is which transfer method will survive real-world scale.
What transfer method fits your library
The right approach depends on size, file mix, and whether this is a one-time move or something you may repeat. For a few small folders, manual transfer is acceptable. For anything with video, lots of nested directories, or hundreds of thousands of objects, I would prefer a scripted method that can retry, log, and resume cleanly.
A practical pattern is to run the migration from an intermediary cloud machine rather than your local desktop. AWS documents an EC2-based approach for moving data from Drive to S3, which is the right mental model if you care about repeatability and not having your laptop become the weakest link in the chain.
| Method | Best for | Strength | Limitation |
|---|---|---|---|
| Manual download and upload | Small one-off transfers | Fast to start, no tooling to learn | Slow, error-prone, and awkward with deep folder trees |
| rclone on a cloud VM | Most business migrations | Scriptable, resumable, and built for both systems | Needs setup and sensible tuning |
| Custom or managed pipeline | Recurring archives and automated workflows | Best for logging, scheduling, and controlled retries | Higher initial setup cost |
One practical detail that often gets missed: Drive-side rate limiting can make lots of tiny files move much more slowly than people expect. In other words, bandwidth is not always the bottleneck. If your archive is full of thumbnails, subtitles, sidecar JSON, and small audio cues, the transfer engine matters as much as the network.
Once you pick the transfer path, the job becomes much easier if you prepare the content properly before the first copy starts.
The transfer workflow I would trust on a real project
For a clean migration, I would handle the work in stages rather than trying to “just copy everything”. That gives you a way to catch naming issues, export problems, and quota-related slowdowns before they turn into a messy cutover.
- Inventory the library. Count the files, total the size, and separate active working assets from old archives. A video team usually has a mix of masters, proxies, graphics, captions, and project deliverables, and they should not all be handled the same way.
- Decide the S3 layout before upload. Map folders to prefixes in a way that is easy to understand later. If the archive belongs to multiple projects or clients, define that structure now rather than trying to tidy it up after the transfer.
- Convert Google Docs into a deliberate export format. Editable copies and archive copies are not the same thing. For collaboration-friendly exports, formats such as DOCX, XLSX, and PPTX make sense. For a frozen archive, PDF may be the better fit.
- Run the first pass conservatively. I prefer a copy-oriented pass with checksum verification rather than a destructive sync on day one. That gives you a safe baseline and avoids accidental deletions while the new bucket is still being validated.
- Throttle rather than fight the source. Google updated Drive API usage limits on 1 May 2026, so a script that worked comfortably before may need retesting if it leans too hard on the source. When you see quota or retry errors, slow the job down instead of hammering it.
- Verify the result in two ways. Check file counts and folder depth, then open a sample of the migrated files. For media libraries, I also like to spot-check at least one long video, one small asset, and one exported document so I am not fooled by only testing the easy files.
- Do a delta pass before cutover. If the Drive folder is still live, run one final reconciliation pass after the bulk copy. That is where you pick up late edits and avoid the classic “almost finished” migration that leaves gaps behind.
If you are migrating large media files, there is another hard limit worth keeping in mind. AWS recommends multipart upload for objects of 100 MB or larger, and multipart upload supports very large objects, up to 50 TB. In practice, that means single-file uploads are fine for small assets, but video masters should be handled as multipart transfers so retries do not force you to start over.
The next issue is format behaviour, because not everything in Drive behaves like a normal file once it leaves the source system.
What happens to Google Docs, permissions, and metadata
Native Google Docs, Sheets, and Slides are not regular binary files, so they need to be exported into standard formats before they can live cleanly in S3. That is the first trap people hit: they think they are moving “documents”, but what they actually have is a mix of Google-native items and uploaded files. Those two categories need different handling.
- Use editable exports when the team still needs to work on the content after the move.
- Use archive exports when the goal is preservation, not editing.
- Keep a note of which files were converted, because the exported name may differ from the source document name.
- Test at least one spreadsheet and one presentation, not just text docs, because each format behaves a little differently.
- Do not assume comments, revision history, or Drive sharing links will transfer as meaningful S3 metadata.
Permissions are a separate problem. Drive permissions are collaborative and document-centric; S3 access is policy-centric. That means bucket policies, IAM roles, signed URLs, and object-level controls replace the easy sharing model people are used to in Drive. If the archive must be consumed by a client, a renderer, or a media workflow, I usually design access rules around the downstream use case rather than trying to mimic Drive’s sharing model one-for-one.
Metadata deserves the same attention. Original timestamps, folder location, and upload dates may be preserved differently depending on the tool, but version history and comments are not something I would expect to survive in a meaningful way. If that history matters, keep Drive as the working layer and treat S3 as the durable archive. That leads naturally into the storage class decision, because not every object belongs in the same tier once it lands.Choosing the right S3 storage class after the move
S3 gives you room to optimise after the migration, which is one of the biggest reasons it is attractive for long-term storage. By default, new objects land in S3 Standard, which is the safest choice for active files. From there, you can decide whether the content should stay hot, move into automatic tiering, or drop into a colder class once it is no longer part of the working set.
| Storage class | Best use | Trade-off |
|---|---|---|
| S3 Standard | Active projects, recent exports, frequently accessed media | Simple and reliable, but not the cheapest for cold data |
| S3 Intelligent-Tiering | Mixed or unpredictable access patterns | Very practical when you do not want to guess the access pattern in advance |
| S3 Standard-IA | Backups and archives that are opened occasionally | Retrieval fees apply, and there is a 30-day minimum storage duration |
| Glacier classes | Long-term retention and true cold storage | Restores are slower, so they are a poor fit for files you may need quickly |
There is one quiet cost detail that catches people out. Standard-IA and One Zone-IA are designed for objects larger than 128 KB, and if an object is smaller than that, S3 still bills you for 128 KB. That matters a lot if your archive is full of tiny sidecar files, manifests, and thumbnails. In that kind of library, Intelligent-Tiering or Standard may be more sensible than trying to force everything into a colder class too early.
For UK teams, I would also choose the region before the first upload rather than after the fact. If data residency, latency, or contractual handling matters, it is easier to land the archive in the right place from day one than to relocate a large bucket later. Once the storage class is settled, the remaining risk usually comes from avoidable migration mistakes rather than the bucket itself.
Common mistakes that make the archive harder to use
- Copying files before defining a naming scheme, then discovering that the bucket structure is awkward to browse or automate.
- Assuming browser upload and download are reliable enough for very large media files.
- Ignoring the fact that many small files are slower to migrate than a few large ones, even when bandwidth is generous.
- Using sync too early and deleting source data before the destination has been verified properly.
- Forgetting to test Google Docs exports, only to find later that the archive contains files in the wrong format for the downstream team.
- Skipping logging and retry logic, which makes it difficult to diagnose quota errors or partial failures.
The most important habit is to think in passes, not in one giant move. The first pass gets the data across, the second pass catches drift, and the final pass proves that the archive can actually be used. That is especially true for digital media workflows, where a missing subtitle file or corrupted proxy can be just as disruptive as a missing master.
My rule for deciding whether to move everything or split the workflow
When I look at a real migration, I usually end up with one of three answers. If the library is tiny and the move is one-off, a manual transfer is acceptable. If the library is large, mixed, or regularly updated, I would use a scripted transfer on a cloud machine and treat verification as mandatory. If the team still needs collaboration in Drive, I would split the workflow: keep active working documents where people edit them, and move finished assets, masters, and archives into S3.
- Small and occasional: manual transfer is enough.
- Large or repetitive: use a scripted bridge with retries, logs, and checksum checks.
- Media-heavy: land the files in S3, then use storage classes and lifecycle rules to manage cost over time.
- Collaboration-heavy: keep Drive for live editing and use S3 for delivery and archive copies.
If I had to reduce the whole topic to one sentence, it would be this: the move is successful only when the files are in S3, the structure still makes sense, and the team can retrieve what it needs without guesswork. That is the standard I would use before calling the transfer finished.